
簡介
大家在研究自然語言時,除了Python之外還有其他程式語言也可以應用,但Python算是較容易上手,而在網站上爬文時發現『Gensim』在自然語言的訓練、擷取、製成model,都可以。
而知道『Gensim』之前我們可能要先知道『word2vec』:
word2vec
word2vec 是 Google 的一個開源工具,能夠根據輸入的「詞的集合」計算出詞與詞之間的距離。
它將「字詞」轉換成「向量」形式,可以把對文本內容的處理簡化為向量空間中的向量運算,計算出向量空間上的相似度,來表示文本語義上的相似度。
簡單的來說:詞向量表示法讓相關或者相似的詞,在距離上更接近。
而本篇介紹不會先介紹到怎樣去訓練自然語言分析的AI模型,而是單純的透過gensim套件解析文章關鍵字。
觀念
在使用套件之前,我們先了解一下自然語言的運作方式,屏除機器訓練那塊,我們可以把自然語言的端想成是在拆解文章,後端就是在處理拆解來的字,並且在後端可以訓練拆解語言的AI模型。
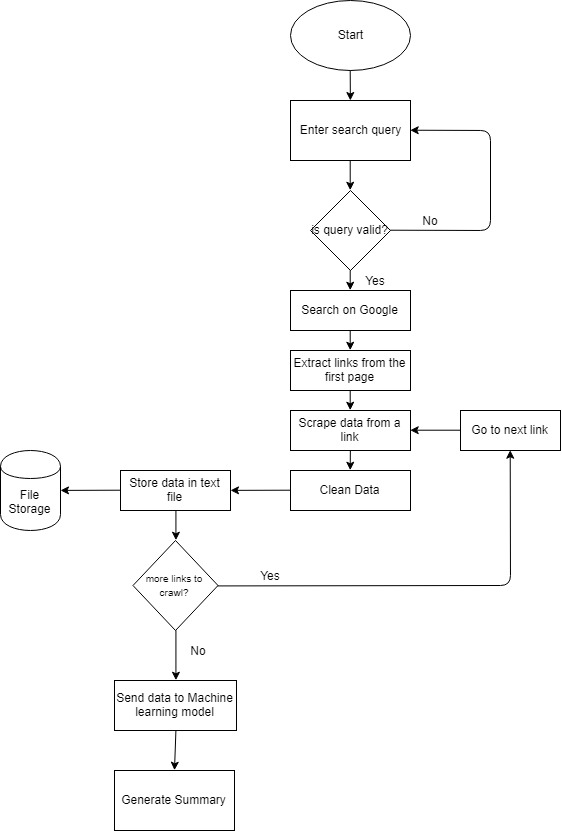
聚焦於前端,有個關鍵字叫『Summarization』,其目的是突出顯示大型語料庫中的重要信息。
– 抽取法(Extractive Method):從原文中抽取部分內容作為摘要。
– 抽象法(Abstractiva Method):了解文章大意後,自動產生摘要。
可以想見抽取法所得到的摘要一定是原文有出現過的(句子、字詞),而抽象法則可能產生出原本沒看過的語句(類似換句話說)。今天要介紹的TextRank演算法是屬於抽取法中常被使用的方法。
而Google也有開發出一套演算法,叫做『TextRank』,觀念一樣是跟上述相同,Gensim套件也是基於該觀念下產出的。
實作Gensim Keyword Extract
pip install --upgrade gensim- 第一步當然就是安裝啦。我是在Atom Editor中的Terminal套件安裝。
from gensim.summarization.summarizer import summarize
from gensim.summarization import keywords- 第二步,引用Gensim中的『summarization』,並且將『summarize』與『keywords』方法都導入。
print(summarize(text))
print(keywords(text , ratio=0.1))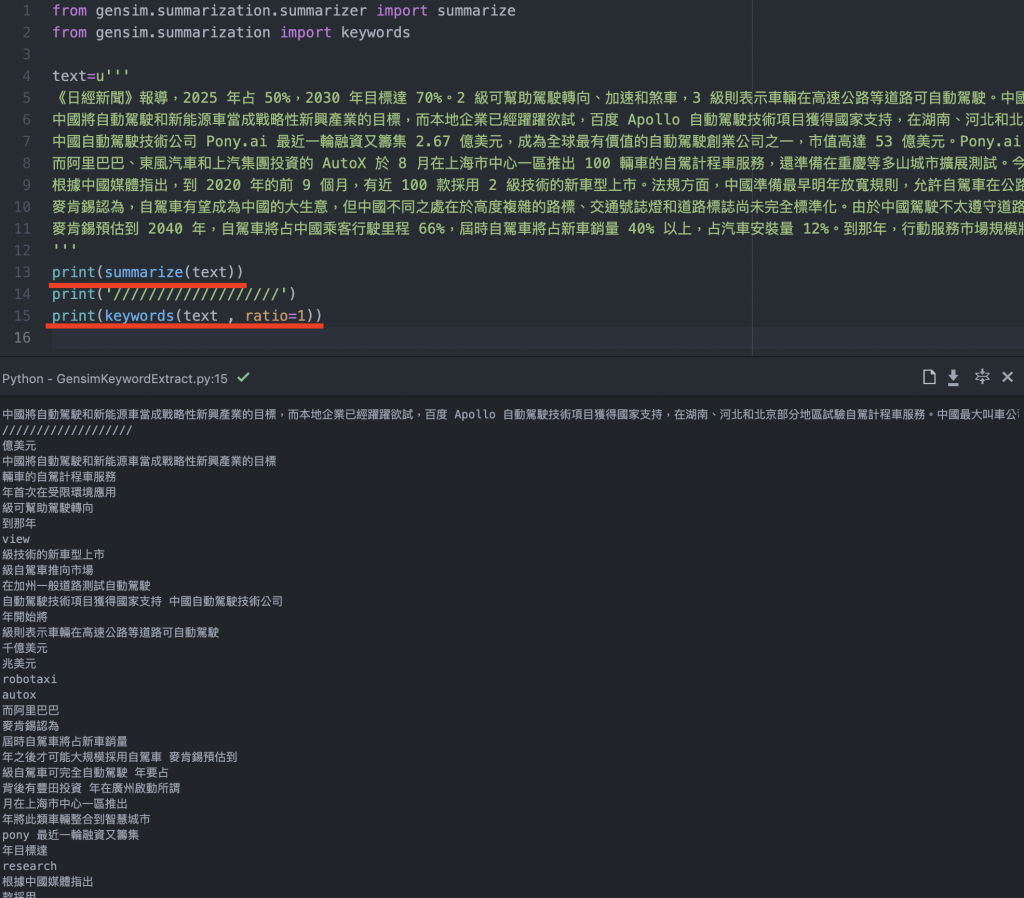
- 第三步,我們先看看他可不可以解析中文的文章,而這邊就會實作keyword與summarize函式,如上圖。
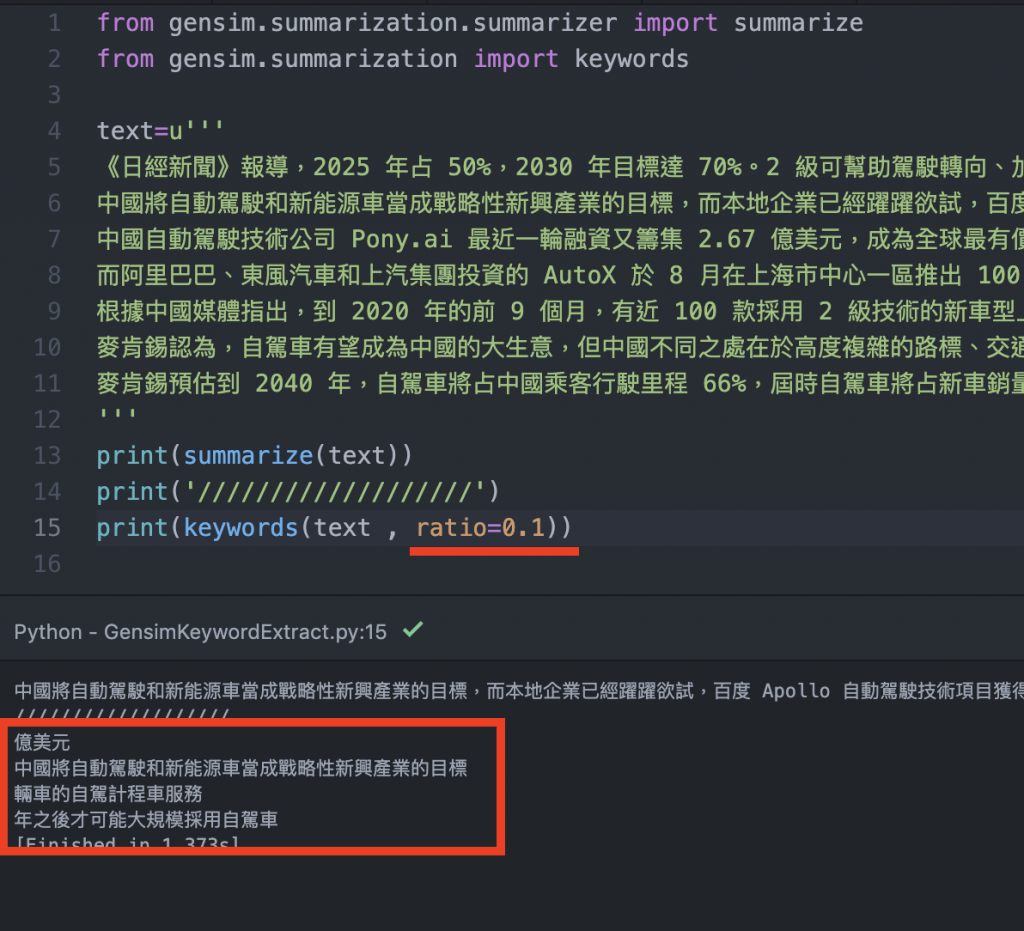
- 第四步,可以看到這兩個方法的長相有點不同,keyword多一個參數『ratio』,這意思就是告知程式我想要擷取的精確程度,數值越大越不精確,越小越精確,但是小到一個程度他可能就擷取不出來,而太大數值到1就會擷取一堆,所以通常會介於0.1-0.5之間。當然該參數也可以用在summarize函式中。
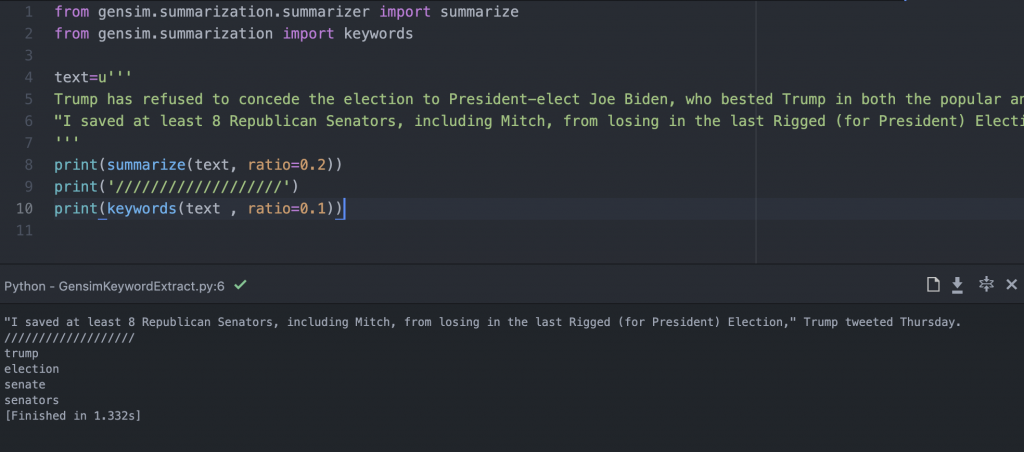
- 第五步,來試試看英文版本,當然也是work的。
小結
這篇我們就先當作進入自然語言的暖身之一,先知道怎樣使用gensim而且來嘗試能不能在你電腦中正常運作,在之後真正使用python來訓練自然語言解析的機器學習時,可以更好上手,當然過程可能沒這麼輕鬆,讓我們一關一關過,祝大家聖誕節快樂。