
簡介
在網路海中找尋有關關鍵字提取的技術時,赫然發現了一個跟Jieba相同的斷詞工具,是由我們國家機構中研院所開發的一個開源工具,叫做GKIPtagger。該機構過去也有開發一個舊版本的斷詞工具,不過在這版本之前,該組織都沒有公開分享過他們研究的成果,只有線上demo版本。
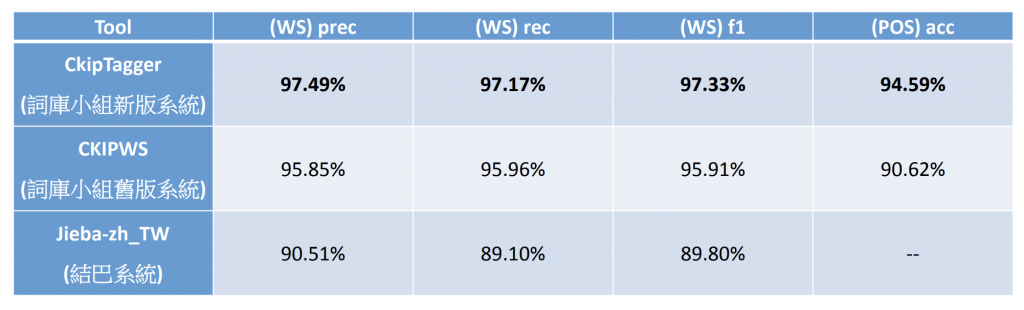
而舊的版本效果跟Jieba差不多,下圖是他們所做的實驗準確率比較表,看來是比Jieba的準確率高了七趴,所以這篇想來試試看它的威力與實作部分。
GKIPtagger 特色
這套工具算是近期才發布的開源套件,而中研院的CKIP Lab demo網站中有蠻多案例,可以去裡面看看。在使用該工具之前,我們可以先看看他有哪一些獨特的點,引用他們網站的敘述如下:
- 結合實體辨識
- 目標是在文字資料當中,能夠辨識出感興趣的專有名詞(包含原本資料庫不存在的新專有名詞),並自動標記正確的分類。
- 目前CkipTagger能辨識11 類一般領域專有名詞及 7 類數量詞,包含:人名、團體、設施、組織、地理、地點、商品、事件、藝術品、法律、語言、日期、時間、比例、錢、數量、序數、數詞
- 支援使用者自訂 參考/強制 詞典
- 從實際應用的角度,能夠支援使用者自訂詞典是一個相當重要的功能。
一般而言,以字為標記單元的機器學習/深度學習的斷詞模型通常因為算法本身的特性,而難以提供使用者自訂詞典的功能。CkipTagger則克服了這個限制,雖是使用以字為標記單元的模型,但仍然支援使用者自訂詞典,包含參考詞典與強制詞典,且每個詞彙均可指定權重,讓使用者能根據自身的任務需求與領域,自行進行系統的客製化
- 從實際應用的角度,能夠支援使用者自訂詞典是一個相當重要的功能。
- 支援不限長度的句子
- 不會自動 增/刪/改 輸入的文字
實操
Step 1 安裝:
該套件提供三個版本讓我們去選擇安裝,分別是以下三種以及TF。
//在安裝下面套件之前請先在你的conda env 安裝tensorflow,版本介於1.13 - 2.0
//標準 - 我選擇這個安裝
pip install -U ckiptagger[tf,gdown]
//簡易
pip install -U ckiptagger
//完整
pip install -U ckiptagger[tfgpu,gdown]Step 2 下載模型:
由於該套件在做每一個斷詞的工序時會去讀取他們訓練好的NLP模型檔案,所以必須要將模型檔案下載在本地資料夾中。下載連結,我這邊是透過jupyter notebook做實驗,而下載下來解壓縮後會是個名為data資料夾,放置位置如上圖所示。
雖然下載模型的方法也可以套過『gdown』套件來下載,但我覺得這樣太慢了,直接下載放在資料夾比較快。
Step 3 讀取模型檔:
from ckiptagger import WS,POS,NER
# To use GPU:
# 1. Install tensorflow-gpu (see Installation)
# 2. Set CUDA_VISIBLE_DEVICES environment variable, e.g. os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 3. Set disable_cuda=False, e.g. ws = WS("./data", disable_cuda=False)
# To use CPU:
ws = WS("./data")
pos = POS("./data")
ner = NER("./data")接著我們要讀取上一步驟下載來的模型檔案,透過CKIPtagger套件的函式,所以要先import近來,並將這幾個函式引數放進路徑。該方法是使用CPU的方式來撰寫。上方有隱藏起來GPU使用方法。
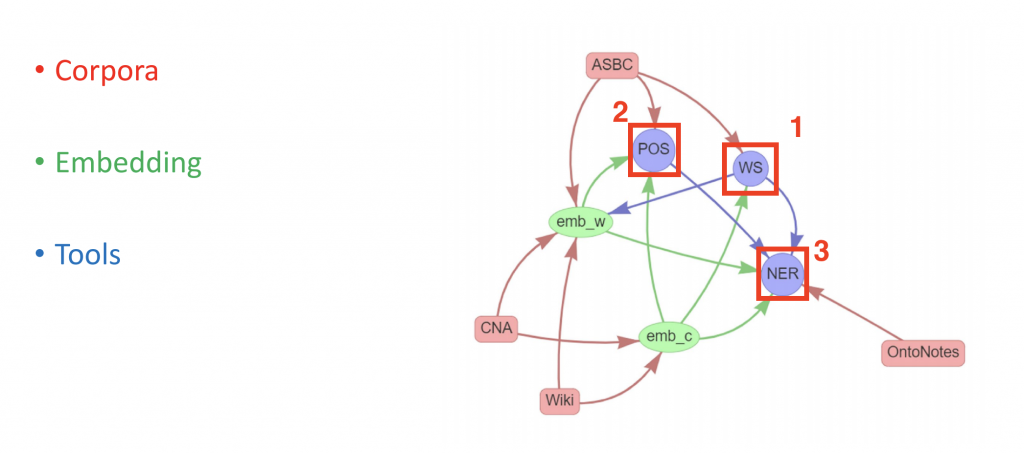
上圖是我片面了解的該套件這三個主要函式的工作流程,WS(斷詞)-> POS(詞性標記)-> NER(命名實體),這流程可能才是產出最佳斷詞的結果,而其中的一些元素可能還要再深入了解一下。
Step 4 放入測試文句與權重設定(選用):

上圖是測試詞句的兩種模式,第一個是官方拿來演繹的資料型態,是使用list,而其實透過字串的資料型態也是可以使用,只是後續的程式寫法也會有所不同。

上圖是在進入主程式之前,可以設定該文章中假如有出現這些文字的話,會讓他提取分數提高,而這區塊是選用的。

另外一個選用的程式碼是釋放記憶體,上圖是撰寫方式。
Step 5 處理區塊:
這邊整理了兩種資料型態的引數處理區塊程式碼寫法,在Step3中有提到,以下是官方提供的list資料型態寫法:
//處理階段
word_sentence_list = ws(
sentence_list,
# sentence_segmentation = True, # To consider delimiters
# segment_delimiter_set = {",", "。", ":", "?", "!", ";"}), # This is the defualt set of delimiters
# recommend_dictionary = dictionary1, # words in this dictionary are encouraged
# coerce_dictionary = dictionary2, # words in this dictionary are forced
)
pos_sentence_list = pos(word_sentence_list)
entity_sentence_list = ner(word_sentence_list, pos_sentence_list)
//實現階段
def print_word_pos_sentence(word_sentence, pos_sentence):
assert len(word_sentence) == len(pos_sentence)
for word, pos in zip(word_sentence, pos_sentence):
print(f"{word}({pos})", end="\u3000")
print()
return
for i, sentence in enumerate(sentence_list):
print()
print(f"'{sentence}'")
print_word_pos_sentence(word_sentence_list[i], pos_sentence_list[i])
for entity in sorted(entity_sentence_list[i]):
print(entity)下方則是字串資料型態引數的寫法:
//執行階段
ws_results = ws([text])
pos_results = pos(ws_results)
ner_results = ner(ws_results, pos_results)
//實現階段
print(ws_results)
print(pos_results)
for name in ner_results[0]:
print(name)Step 6 成果:


可以看到提取的結果有些微的差距,大家都可以選用這兩種不同的引數與實現方法。
小結
透過實操後,我們知道了要怎要使用這開源工具,在後續我想透過斷詞來擷取整個文章的關鍵字提取,如此一來應該可以更準確的抓到與本文近乎相關的關鍵字吧,秉持著實驗的精神來嘗試,如有成果將會分享一篇精準抓取中文文章關鍵字。另外也會研究一下『NLTK』其他語系的斷詞與關鍵字提取的工具研究。