
簡介
在網路上的open source有蠻多別人寫好的套件,我也在專案中嘗試過一些的套件並應用之,今天要分享的這篇算是最易用也最精準的可以得到你要的新聞元素,例如新聞的圖片、新聞的標題、內文等等等,就容我以功能為標題來介紹該套件,這樣比較清楚。
安裝套件 與 初始化
Newspaper3K,在文件中好像只能用在Linux與MacOS,Windows可能要再找找有沒有使用方法。言歸正傳,我們依然要先安裝該套件。
pip install newspaper3k接著我們要在你程式中初始化,以下是初始化的程式碼
from newspaper import Article
URL='https://news.housefun.com.tw/news/article/208227269532.html'
article = Article(URL, language='zh') # Chinese
article.download()
article.parse()
article.nlp()可以看到上面程式碼,我們要先import newspaper,並在程式碼中以Article可以再編輯器中使用。
而這套件是透過url來抓取新聞內容,他的套件裡面應該也是用BeautifulSoup來解析,但他解析出來的內容大概有百分之98%的精準。所以假如你要大量抓取就可以融合GoogleNews套件+for-loop來無限抓取。
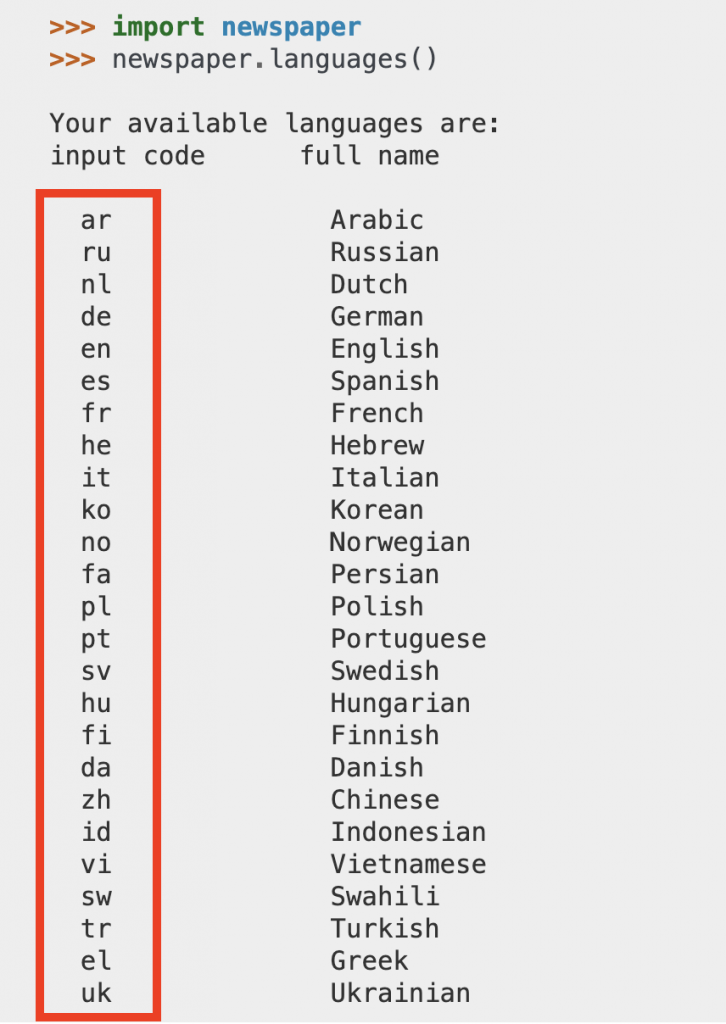
而初始化的程式碼就是下面這四行,當然要先把url塞在函式參數中,並且指定新聞的語言,如上圖所示,該套件也提供許多的選擇。
接著要呼叫『download()』來下載整個頁面,並且使用『parse()』來解析,再透過『nlp()』來抓取關鍵的元素,下面分別是Parse與Nlp所抓的元素。
Parse
- 獲取文章標題
- 獲取文章作者
- 獲取文章日期
- 獲取文章頂部圖片
- 獲取文章影片連結
- 獲取文章本文
NLP
- 從本文中提取關鍵字
- 獲取文章摘要
- 獲取網頁中所有圖片
- 獲取html內容(html程式碼)
Parse – 呼叫方法
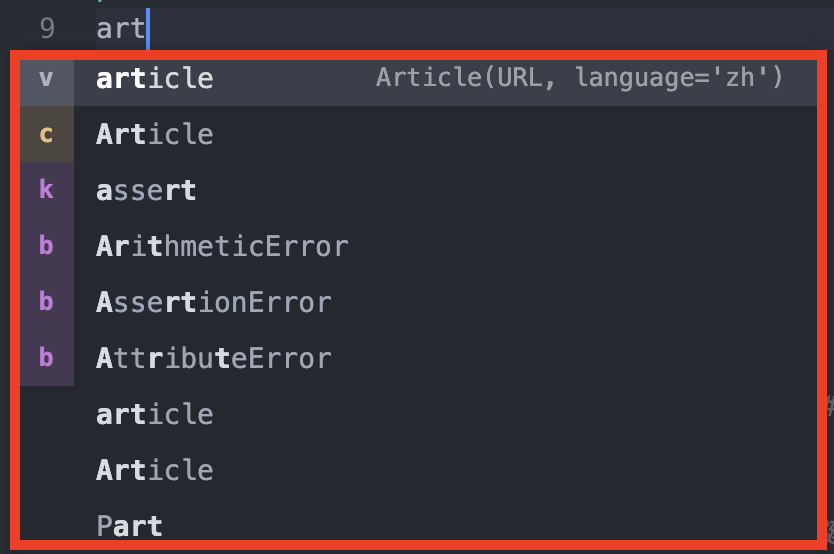
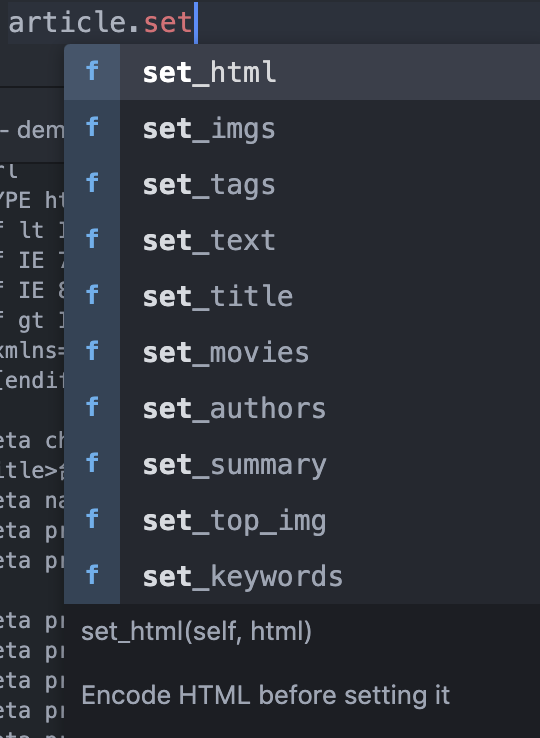
在寫程式之前,大家可以先安裝一下一個不錯的套件,可以自動幫你找到類別或模組中的函示與方法,叫做『autocomplete-python』。當我們在編譯的時候,就會自動列出,如上圖二。
print("標題:",article.title)
print("作者:",article.authors)
print("發文時間:",article.publish_date)
print("主要圖片:",article.top_image)
print("影片連結",article.movies)
print("全文",article.text,"n")
print("限制字數"article.text[:150])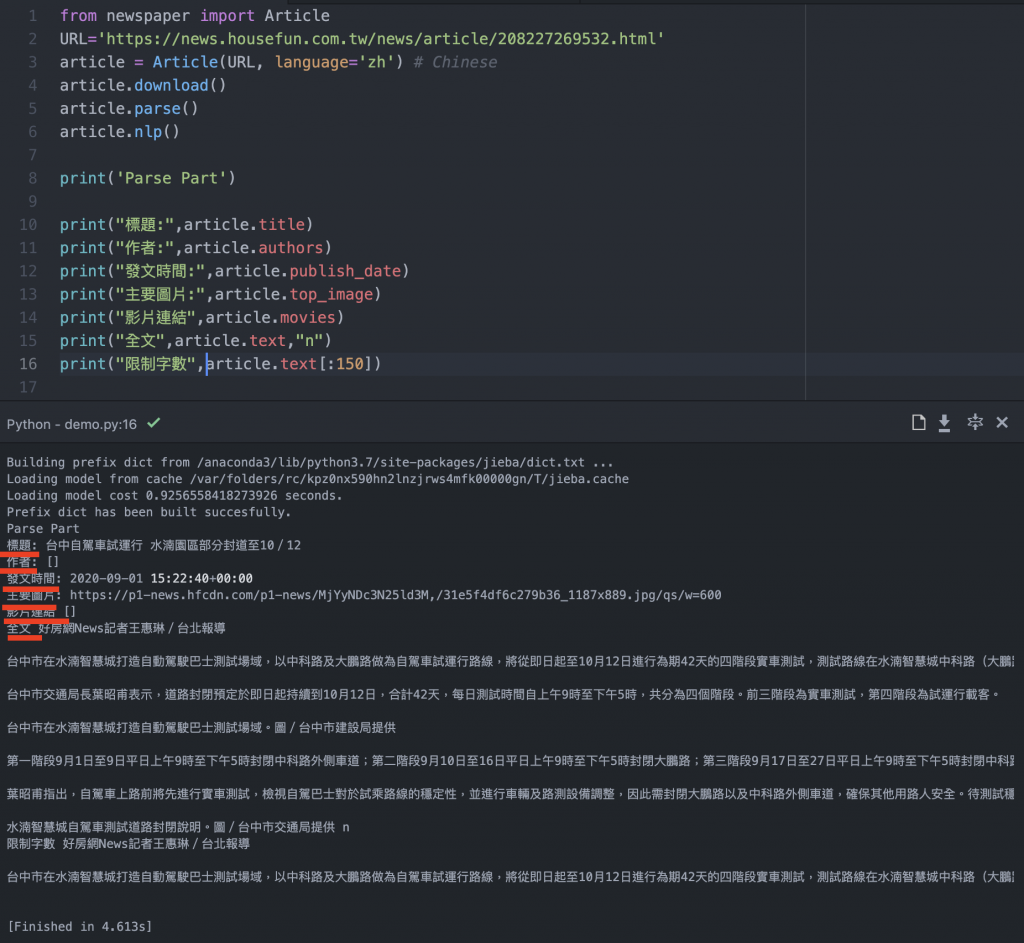
如上述程式碼,在每個功能有標注抓取的項目,大家都可以複製拿來跑跑看。如上圖,這是我跑出來的效果,我也換過不同的新聞平台,他幾乎都可以抓到你要的資料。
但是你看到上圖有一些[],這種符號,這就代表該篇文章這個元素是沒有的,在這邊小註解一下。
還有一個地方是,本文可以透過字數限制來顯示之,如上圖所示,『article.text[:150]』,取得內文的前150字元的文字,印出來就只會顯示150字元。
NLP – 呼叫方法
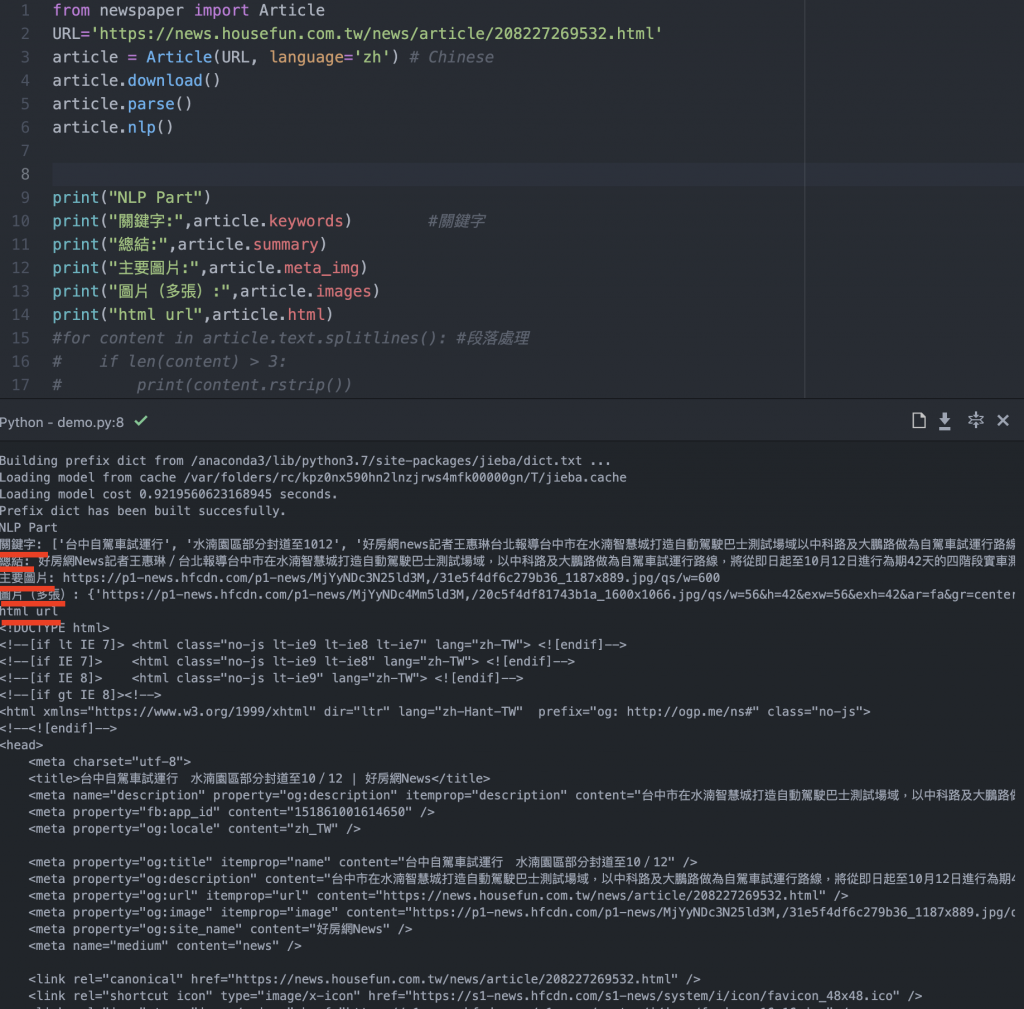
print("NLP Part")
print("關鍵字:",article.keywords)
print("總結:",article.summary)
print("主要圖片:",article.meta_img)
print("圖片(多張):",article.images)
print("html url",article.html)而NLP的用法一樣跟Prase相同,大家也可以直接複製程式碼來玩玩,NLP的意思其實是語意的分析,所以經過這套件過濾出來的元素都比較像過濾過本文進而產生關鍵字、結論等等。
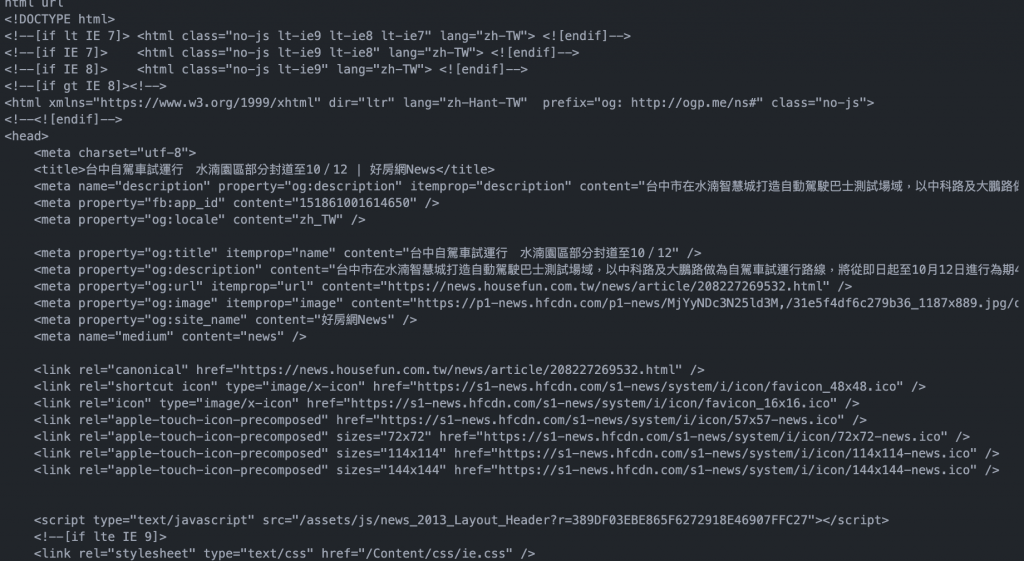
這邊也有一個要提到的,在『html』這個函式,跟requests這套件一模一樣,我在想該作者是直接使用requests換個皮而已,如上圖,產出的內容就是Html的code。
小結
我只能說這套件非常的好用,不僅僅是可以抓資料下來,也可以將網頁上的資料做改變,假如你有權限的話,但我還沒有嘗試過,有空可以玩玩。
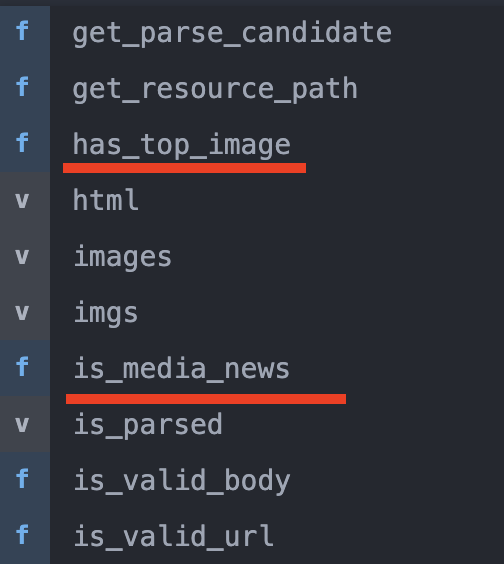
在抓取想要抓的元素前,也可以透過該套件先判斷後,再決定要不要執行,如上圖,是否有主圖?或是否是有影片的新聞等等,其他細部功能再之後有遇到且直得分享的,我再來紀錄分享。