
簡介
我們通常找資料絕大部分的人都是使用Google搜尋平台,而我們假如要爬資訊,雖然說Google News所找到的文章或報導真實性比較高,但有時不像直接從搜尋平台找到的內容還要廣,但卻有可能不太正確,不過不管,這邊我想要透過Python來自動搜出我想要的資訊。
實作
在進行時做之前,我們當然是想要達到最終目的,就是拿到整個網頁的圖、文字、標題等等篩選過後的資料,而在之前有介紹過一些套件可以解析網頁並拿到資料,例如:
Newspaper3K
Request + BeautifulSoup
而我們在擷取資料之前,必定要拿到搜索出來結果的網址,這就是這篇想要分享的工具。
Step1 : 首先一樣我們先安裝,而我有上自己測試過的程式碼在Github上,大家複製下來開啟demo.py檔案執行即可。
pip install beautifulsoup4
pip install googleStep2 : 匯入該套件在檔案中。
from googlesearch import searchStep3 : 這邊介紹一下Search()的參數,但下方是最基本的使用方式,一定要有「關鍵字」。
Searching = search("tesla revenue 2021")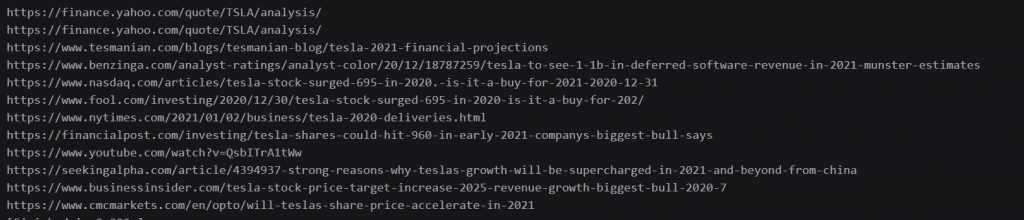
可以看到上圖,透過這函式將會搜尋出預設10筆的結果並儲存結果網址。
Step4 : 參數介紹 :
search(query, tld='com', num=10 ,lang='en')- query : 搜尋關鍵字區。
- num : 要搜尋的筆數。
- lang : 要搜尋的語言。
Step5 : 執行結果,如下圖一,我們可以手動比對一下搜尋果如下圖二,果然結果是一樣的,沒有特別精準或是不精準。
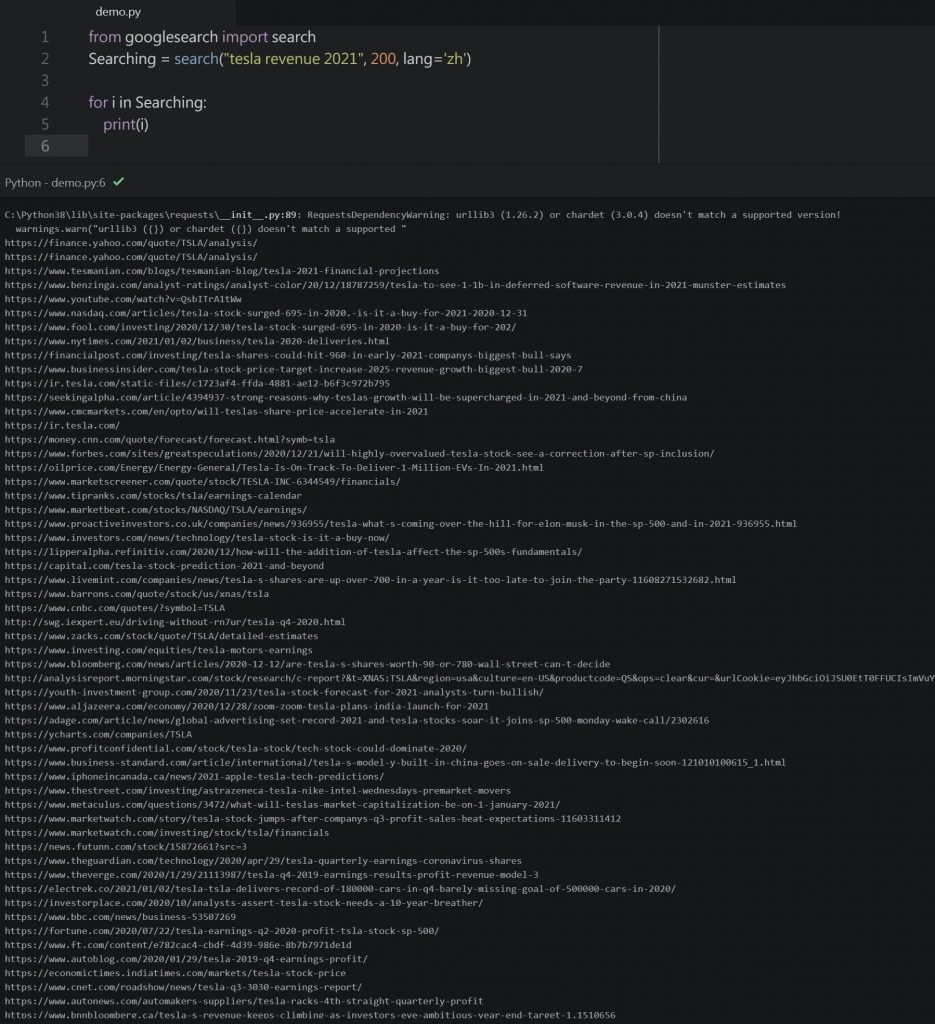
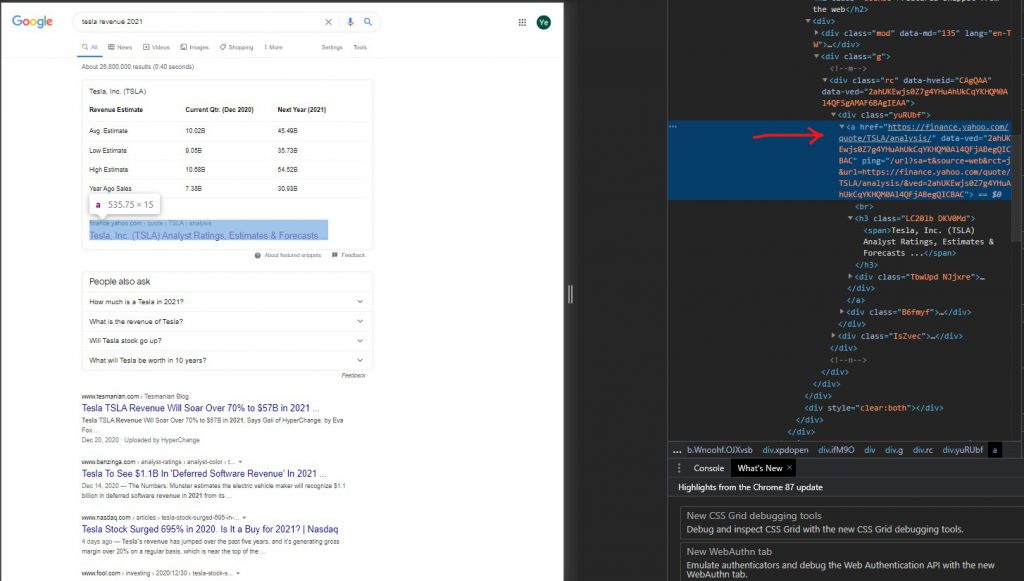
小結
當然google公司也有自己開API供使用者作應用,但就是用到一定數量,就是須要收費了;另一方面,也有一些人研發了googlesearch,但年代有點久遠,不然他提供的參數更多,讓我們在使用上也會更靈活。
這篇簡單介紹了這個小工具,讓我們可以得到搜尋引擎搜出來的網址,下一步驟就可以將網址導入擷取工具,去擷取我們要的資料,雖然selenium也可以做到,但我們多學多了解一個工具也是不錯的。