
簡介
在上一篇我們有分享到比對字串是否相符的一些基本方式,但那些都是透過簡單的關鍵符號判斷,不是說上一篇介紹的方法不好,是有時候需要大量比對,或是特殊比對,可能就要用到別人開發好的套件,這篇就介紹其中一種,叫做『 difflib』。
就剛剛講到有非常多的比對class方式,這篇我們就只講一個『 SequenceMatcher 』這個類別就好,不然太多類別一篇講不完,也太多難吸收。
difflib
difflib模組提供的類和方法用來進行序列的差異化比較,它能夠比對檔案並生成差異結果文字或者html格式的差異化比較頁面,如果需要比較目錄的不同,可以使用filecmp模組。
實作
我們就用實作來跟大家介紹其中 SequenceMatcher Class要怎麼應用:
範例1:單純SequenceMatcher用法

不免俗的要先安裝並import difflib套件,我們可以看到上圖,假設我們有兩個字串想要做比對,就先把兩字串容器新增比給予他值,接著我們就使用『 difflib.SequenceMatcher() 』類別。
SequenceMatcher ( 要去除的文字或空格或符號 , 字串一 , 字串二)
以上是該類別需要丟進的引數,第一個範例我們先不必去除字串中的任何字或符號,單純來比對一下,可以看到印出來的值為 0.857..,這邊說一下這個值的用意,越趨近於1的代表越相似,越趨近於0的就越不相似,大家可以自行嘗試看看。
範例2:去除字串中的字元比對
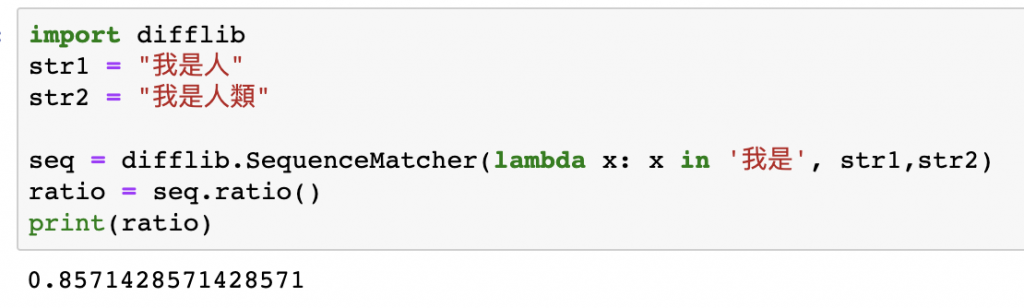
範例一有提到引數1中可以填入要去除的字,這篇的去除其實是程式會自動略過該引數的字串繼續去比對,所以大家可以使用看看,可以看到印出來的數值是一樣的。
範例3:找尋匹配的大小 find_longest_match

在SequenceMatcher類別中還有包含了許多的匹配方法,該範例的『 find_longest_match 』就是要找匹配的Size,講白一點就是匹配的長度有多少,如上圖所示。
find_longest_match( 從字串1第幾個字元開始找 , len(str1) 判斷字串的長度 , 從字串2第幾個字元開始找, len(str2) 判斷字串長度)

我們了以驗正一下這個函式的處理方式,在兩個字串中動點手腳,再次執行時可以發現兩字串就只有『 我是 』這兩個字串是相符的,所以印出來的結果,果真是如此。
上網爬一下文發現他是有一套演算法,叫做『 *Longest Common Subsequence(LCS) * 』基因定(DNA)序演算法。
範例4:取的字串相符的區塊 get_matching_blocks()

該方法是將匹配相符的所有區塊都記錄下來,如上圖,我們人工可以辨別出相符的有『我是人』,但是兩字串的相符位置是不同的,程式會拆成區塊來分析,處理流程是『我是』『 空格 』 『 人 』三個區塊並會記錄位置,其實他的方式有點像將字串1的每個單字去跟字串二比對,當遇到不同時他就會單獨儲存在一個新的區塊中。
小結
當然在比對字串的套件不只有本篇介紹的difflab一種而已,其實還有Levenshtein,這兩套件是比較常看到大家會使用的,在本篇有介紹difflab對字串比對的不同方式,例如全局比對、區塊比對、比對相符長度、取出比對後區塊等,其實還有蠻多的difflab函式可以使用,我大概取出比較好用且簡單的函式來介紹,大家都可以選擇最符合自己專案型態的範例還使用之。有機會可以再研究一下其他方法來分享。