
簡介
在Python中有許多的關鍵資料型態,例如int , string , bool , float等等等,每一個資料型態的使用方法都不同,今天想記錄一下『String』這資料型態的化學反應,也就是透過該資料型態的函示、方法來改變為自己想要重置的狀態。
字串大小寫轉換
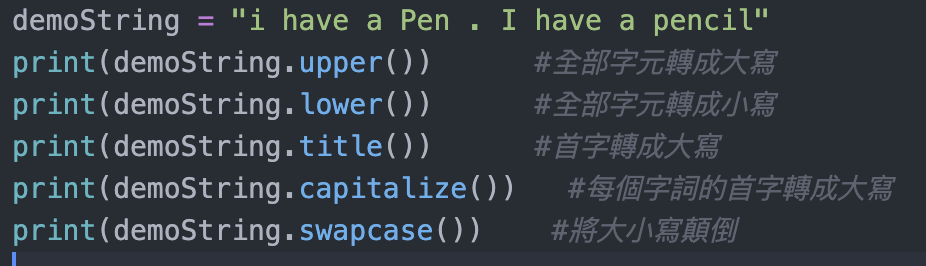
最常使用的方法當然就是最簡單的類別方法,將字串做大小寫的轉換,通常會用到檢查文章的字首,或是在判斷使用者輸入帳號密碼,看是要全部大寫還是全部小寫供寫程式的人自由運用。
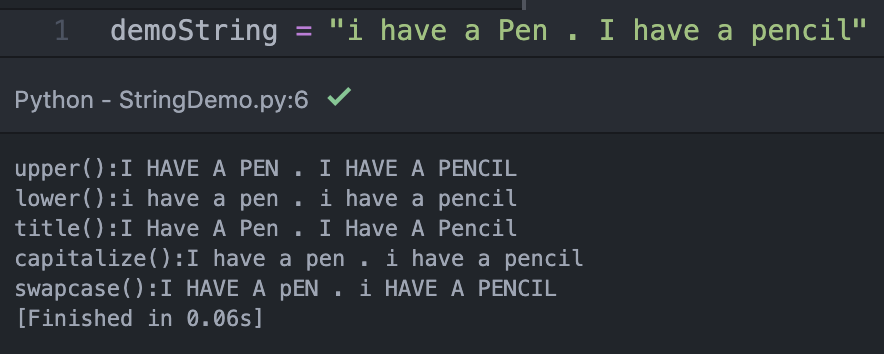
可以看到上圖,在印出來的視窗,大家可以跟原始String比對類別與印出來的結果做比較。
字串的空格處理
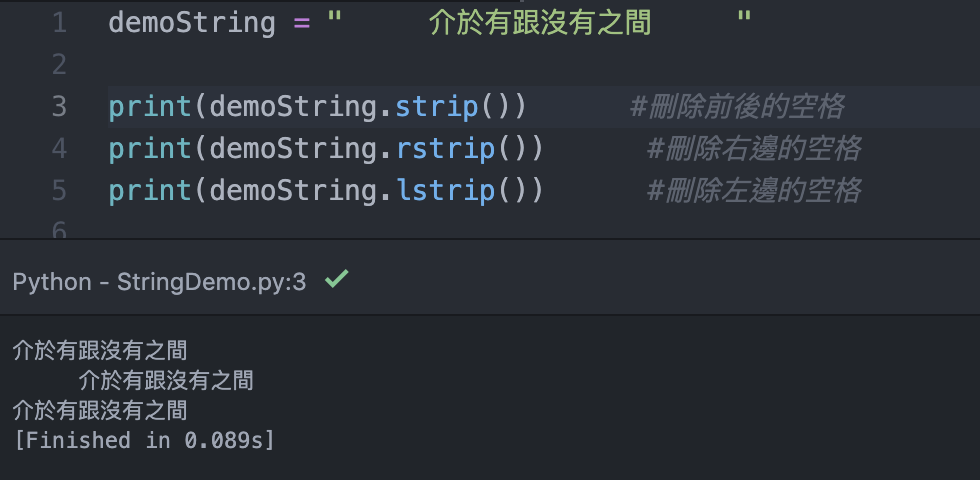
接下來是空格的處理,這類的方法,通常在透過爬蟲抓取網路文章時,文章中可能某些文字有人會按下很多空格等等之類的空格處理,在上圖的三個方法就是去除空格的三種類別。『strip()-去頭去尾空格』、『rstrip()-去除右側空格』、『lstrip()-去除左側空格』。
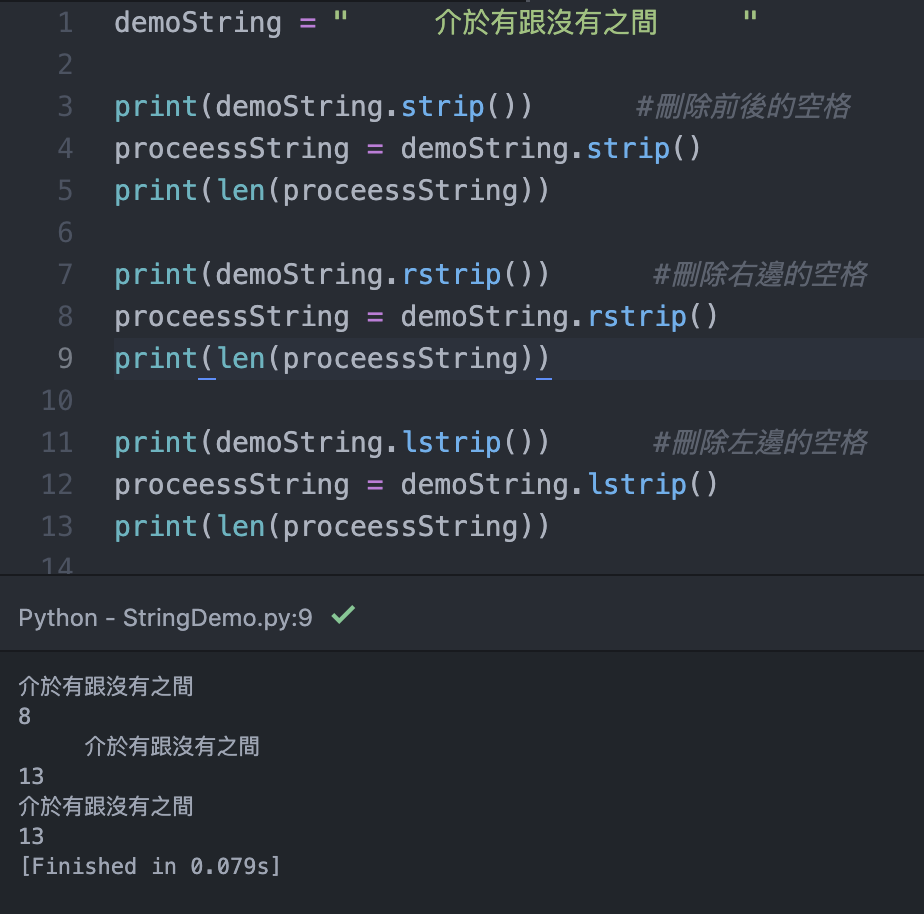
從剛剛印出來的結果有點難看出來有沒有刪除,尤其是刪除右側空格的方法。所以我們就刪除完並偵測字串長度就可以明顯看出。
字串查詢,替換,拆解
我們先看看怎樣查詢一段文字的字元在哪裡,這樣才能作後續的動作。下方列出幾種查詢的方法:
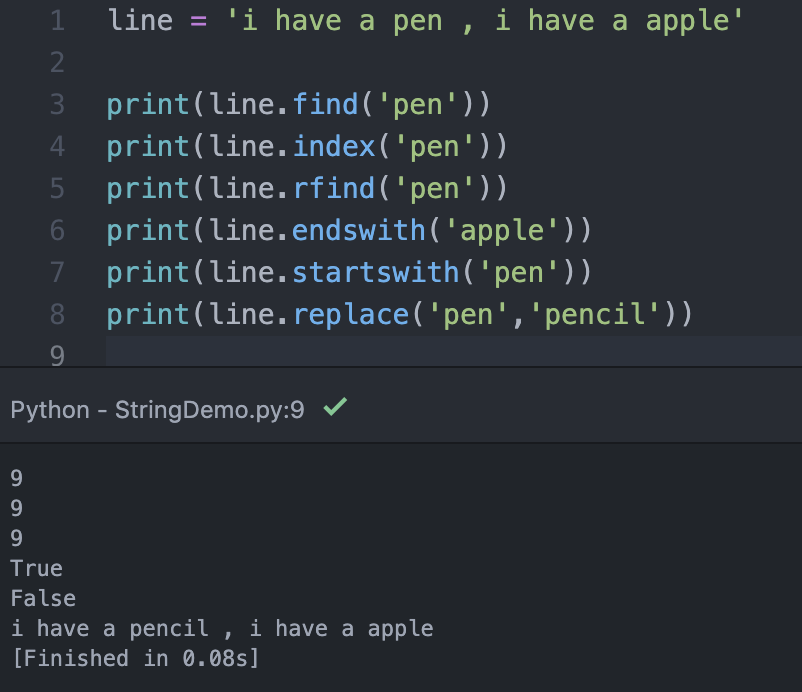
- find() : 查詢子字串在字串中出現的索引,若搜尋不到子字串,會回傳-1
- index() :查詢子字串在字串中出現的索引,若搜尋不到子字串,會回傳ValueError
- rfind() :從尾部往前查詢子字串在字串中出現的索引
- endswith :檢查字串尾部的子字串
- startwith :檢查字串頭部的子字串
- replace :尋找有無相符的字並替換子字串
透過上方查詢方法了解過後,我們接著進行拆解,大家可以看到replace(),算是最快的字元替換方式。
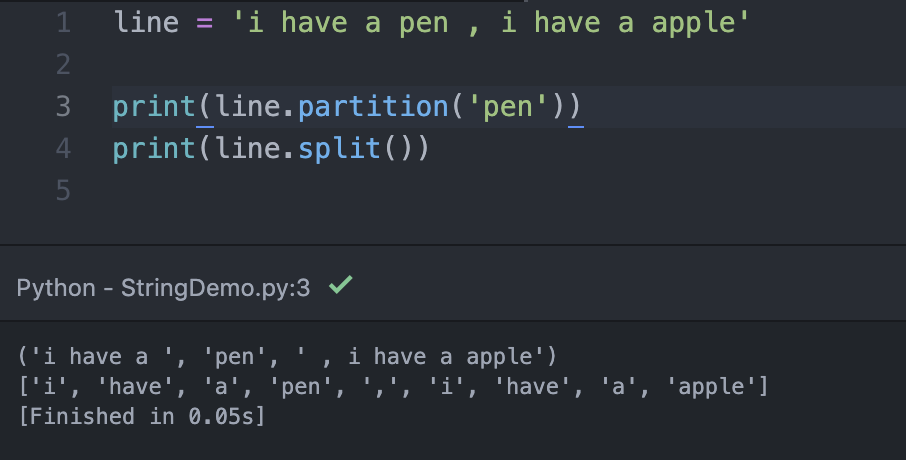
而到了字串拆解的階段,大家可以看到上圖,我覺得比較常用的就是『split()』,他就是把所有字詞所有進行拆解,包含標點符號,『jieba』我想這套件就是使用python的原始方法來拆解並替換字詞。
值得一提的是『partition()』這方法,他會去找尋你輸入的文字,並把該字單獨拆出,並且把前後的字串個別列為一組字串。
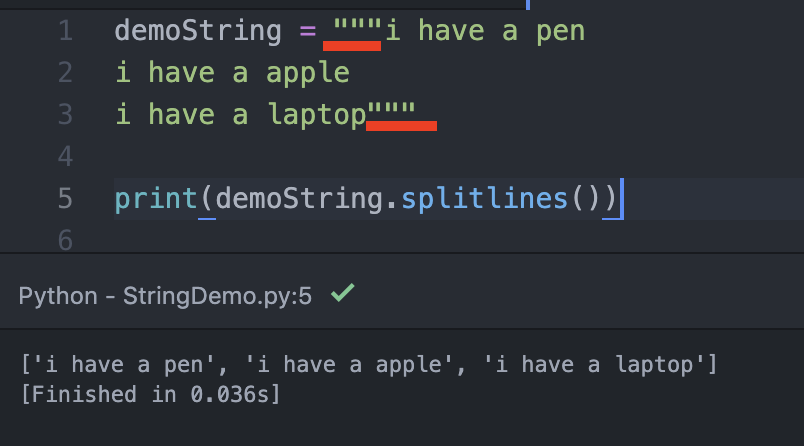
再講講一個很重要的功能,在Python中,你假如字串要有空格的話,你的引號要向上圖這樣『”””』頭尾都要輸入這種引號,才可以按下Enter做換行。
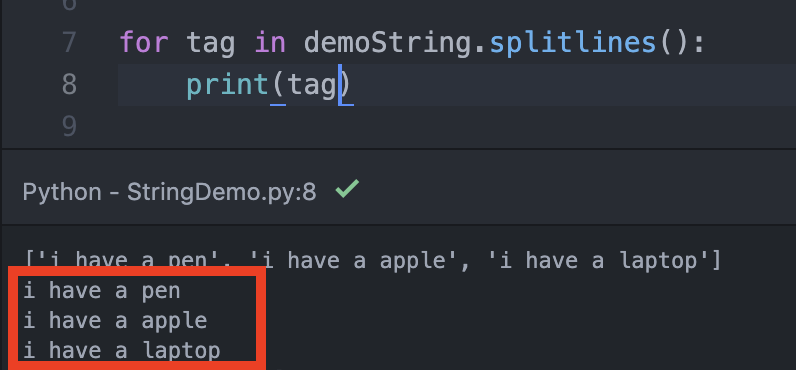
『splitlines()』,這個方法是非常重要的,在網路爬蟲抓到的文章內文,假如他們含有空格符號,該方法會自動去除,只取文字部分,透過for-loop即可將每一句話一句一句的印出。如上圖。
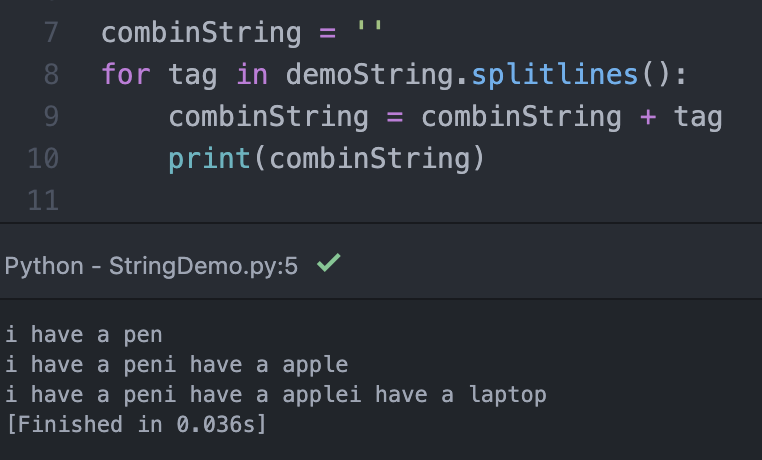
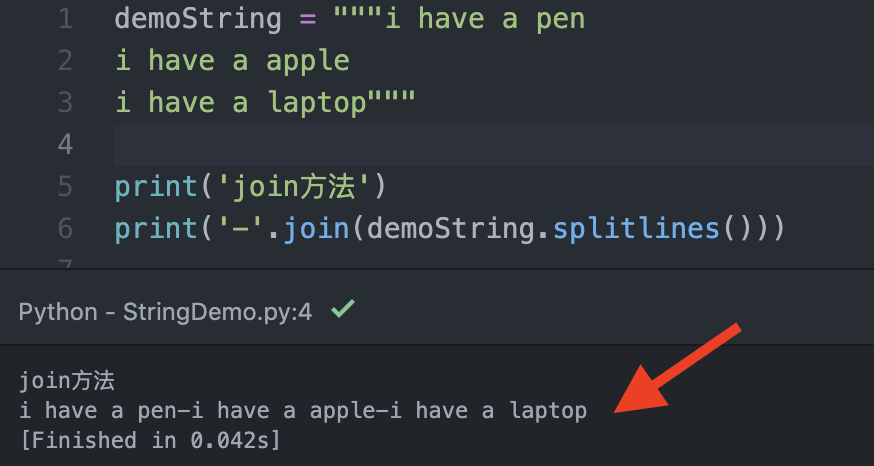
看過上段的拆解之後,當然也要有合併的方式,上圖一是最土砲的做法,但很不靈活,所以大家可以看到圖二,Python有提供『join』將字元字串合併的方法,並且可以指定合併間的符號,在這邊就做個紀錄一下。
字串格式化
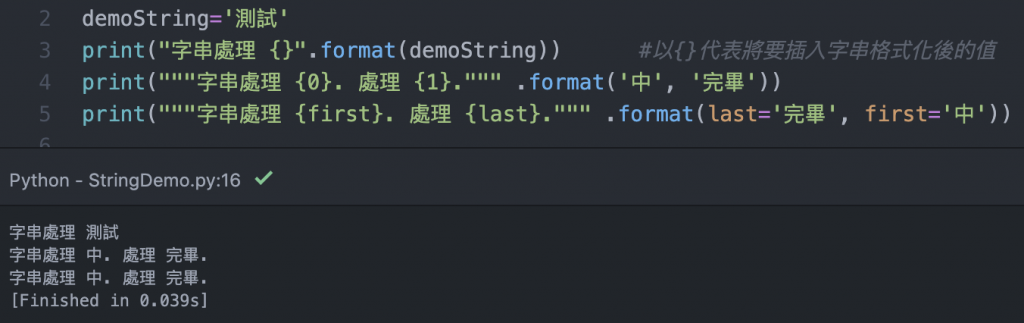
這邊先講講簡易的格式化,在字串格式中,我們也可以透過格式化的方式來替換文字,如上圖,在字串中想要替換的區塊可以用『{}』來當錨點,並在字串後使用『.format(字串)』,如第一行。
看到第二行跟第三行,我們可以再把第一行的錨點加工一下,加入索引值,我覺得最方便的就是用數字索引,與C#用法相同,一樣在字串後面加入『.format(有幾個索引就放幾個,並用逗號來分割)』
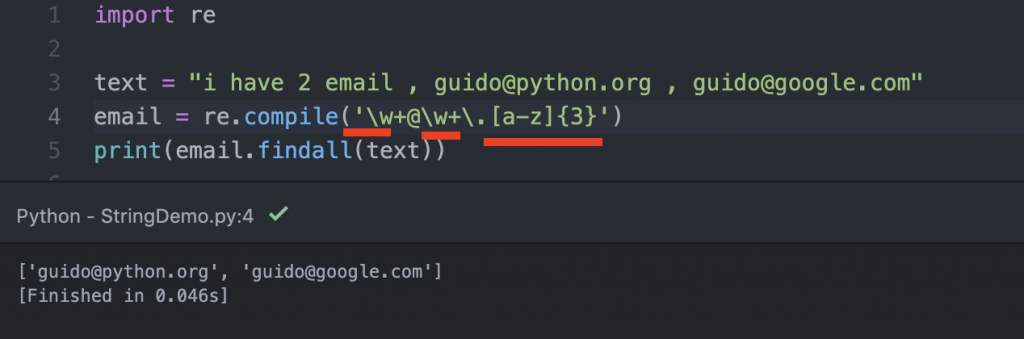
在python中,我們使用格式化來搜尋的話,就要用『re.compile()』並在括弧內將要把格式化的替代字元填入,並且看你要吐回怎樣的結果都安插好在括弧中,就把這當成正規化搜尋的公式,下方是最常見的正規化匹配代碼。
| 字元 | 描述 |
|---|---|
| d | 匹配任意數字 |
| D | 匹配任意非數字 |
| s | 匹配任意空⽩字元 |
| S | 匹配任意非空⽩字元 |
| w | 匹配任意字⺟和數字 |
| W | 匹配任意非字⺟和數字 |
最後再把要搜尋的一段文字容器使用『.findall(剛剛制訂的公式)』來搜尋關於本案例要找文章中有出現email的內容,印出來就是都是email的內容了,要注意的是『{3}』,這邊的用意是取[a-z]的三個字元。
小結
文章爬蟲,通常抓下來的內容,百分之80可能都是有缺角的,不是空格太多,不然就是有換行等等的格式,我們全部抓下來之後,肯定要再透過一些程式來將內文符合我們要的樣子,在未來重置文章,或做內容農場時,在應用上可以更統一、更有效率的使用之。