
簡介
這次又要分享一個別人開發好的工具,在抓取新聞或是網路論壇文章時,假如在頁面中,作者已經有列出本文關鍵字的話,就不需要透過本工具來分析文章內文來找尋關鍵字,可以直接使用request+bs4工具來抓取,反之就必須透過擷取關鍵字的工具來抓。
在提取關鍵字中有一個技術叫做RAKE, RAKE是快速自動關鍵字提取算法的缩寫,它是一種關鍵字提取算法,透過分析單詞出現的頻率及與本文中其他單詞的出現次數程度來嘗試確定文章中的關鍵字。 而接下來就實際操作一下。
實際操作
rake-nltk Github
Step1:大家可以先到上面網頁去下載整包檔案,接著可以透過jupyter notebook來實際寫程式來嘗試了解此工具的做法。
Step2:如上圖,請安裝「!pip install rake-nltk」套件。
#基本用法
from rake_nltk import Rake
#進階用法
from rake_nltk import Metric, Rake
#Step3:引入rake-nltk套件中的Rake()類別。如上述,有分兩個引入方法,一個基本,一個進階,大家先用基本用法就好。
my_article = """
Apple has gifted the world with a library of devices that have since become household names, many of which we use daily. There’s the iPhone, iPad, MacBook Pro, and AirPods; but when you think Apple, Car is not the first word to come to mind. That might soon change as recent news has breathed new life into over ten years of rumors surrounding Apple’s attempt at an electric car. Here’s everything we know so far, along with the winding road of a backstory that brought us to this point.
"""Step4:放置想要分析文章的文本字串資料。
#分析字詞
r.extract_keywords_from_text(my_article)
#分析字句
r.extract_keywords_from_sentences(my_article)Step5:接著就要進入分析的主要的方法,一個是以字詞的方式來分割文章中的「單字」,另一個是以字句的方式來分割文章中的「句」。
r.get_ranked_phrases()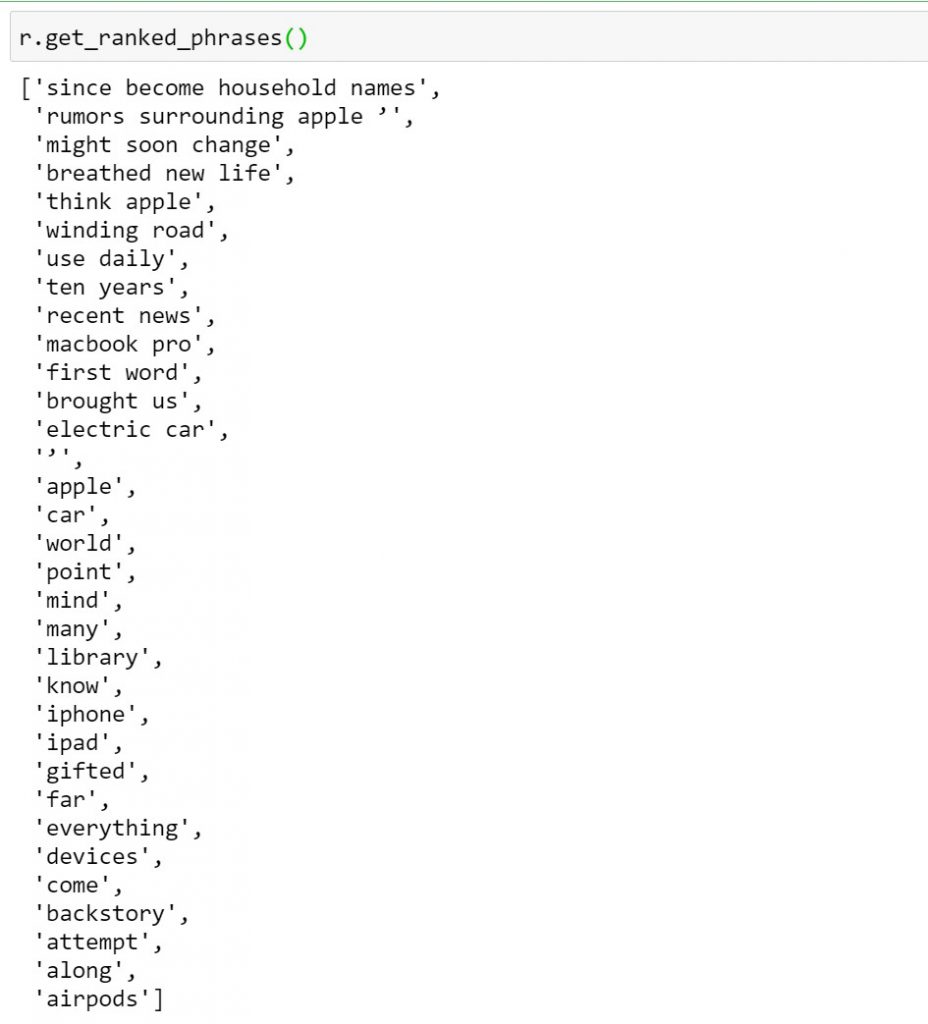
Step6:而當你選定好要用字或是句來分割的方法後,接下來就進入提取關鍵字或句的程式碼,如上。分析字的結果如上圖,他將每一個片語、單字等等與句符合的都存在陣列中。
r.get_ranked_phrases_with_scores()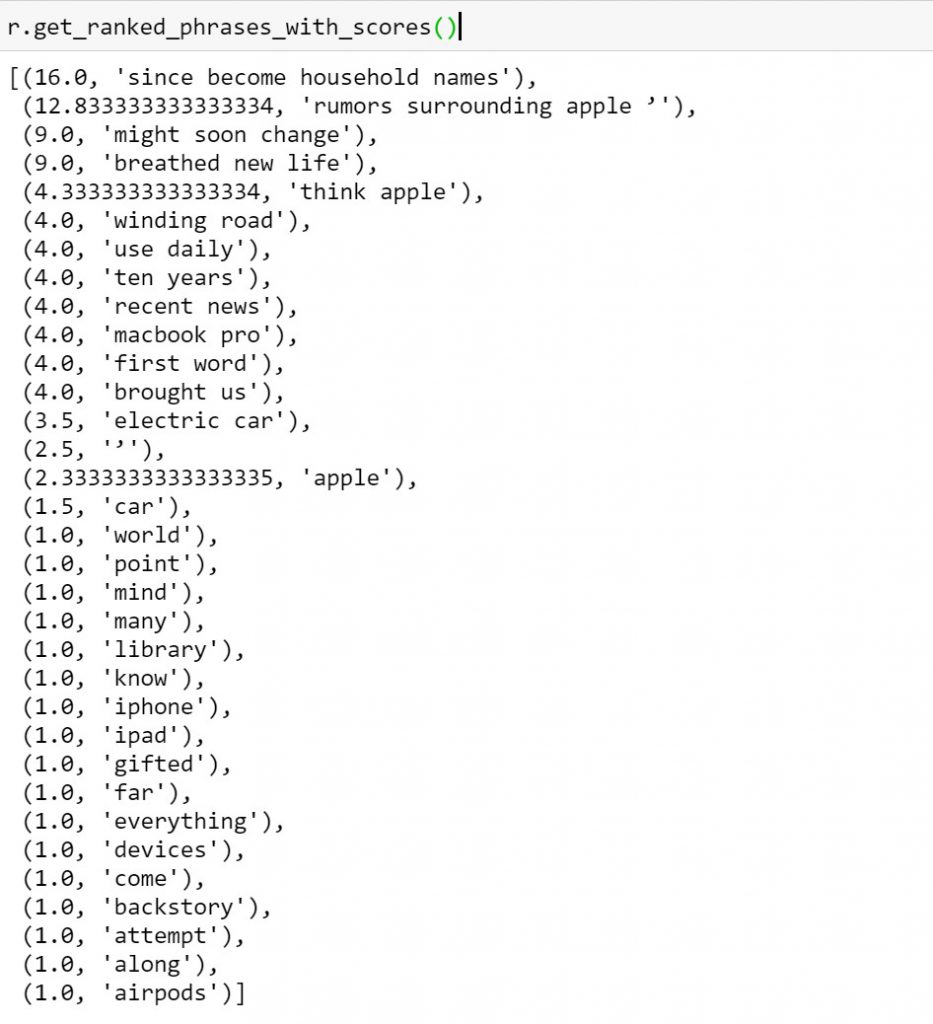
Step7:上述列出的關鍵字這麼多,而我們要怎樣知道哪個是最接近本文的,可以透過上面程式碼知道,他會將每個字的相依做Rake排行。如此基本的用法就已完整實驗完成。
from rake_nltk import Metric, Rake
# 要將其與nltk支持的特定語言一起使用
r = Rake(language=<language>)
# 如果您想提供自己的停用詞和標點符號,例如(is,a,to,did...等等)
r = Rake(
stopwords=<list of stopwords>,
punctuations=<string of puntuations to ignore>
)
# 如果要控制排名指標。使用d(w)/ f(w)作為指標,可以將此API與以下指標結合使用:
# 1. d(w)/f(w) (Default metric) Ratio of degree of word to its frequency.
# 2. d(w) Degree of word only.
# 3. f(w) Frequency of word only.
r = Rake(ranking_metric=Metric.DEGREE_TO_FREQUENCY_RATIO)
r = Rake(ranking_metric=Metric.WORD_DEGREE)
r = Rake(ranking_metric=Metric.WORD_FREQUENCY)
#如果您想控制詞組中的最大或最小詞,將其設為考慮排名,以Rake實例:
r = Rake(min_length=2, max_length=4)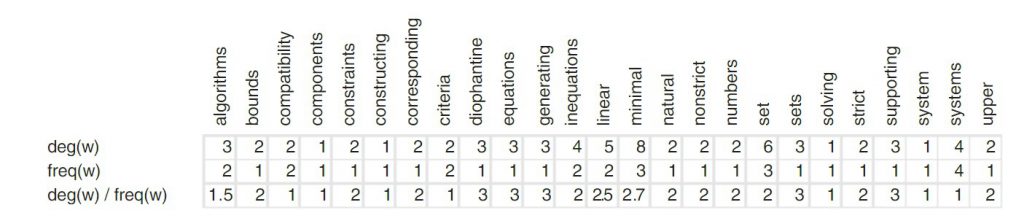
Step8:上面程式碼中是作者提出的一個進階用法,大概意思就是可以放置你要過濾掉的「stop word」,並且將工具Rake出來的關鍵字作權重的調整,d(w) , f(w)的權重示意如上圖。
小結
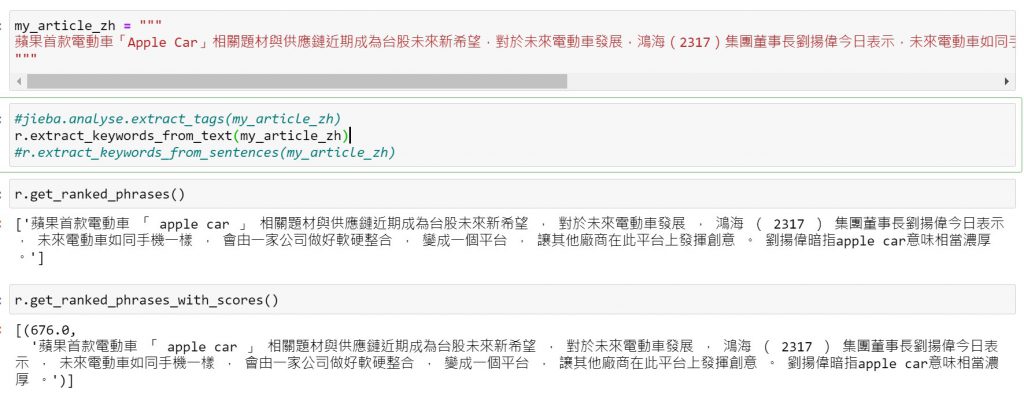
雖然本工具只限用英文版的,應該說較適用英文版,但是我還是白目的嘗試中文,配合Jieba,如上圖,看來是不盡理想,還是用之前介紹過中文關鍵字的提取就好,工具要用對地方。