
簡介
這次我想分享一下有關新聞爬蟲的相關套件,之前我們在爬新聞時,有使用過google news來當作搜尋引擎,只要透過python程式碼輸入語言、關鍵字等,就可以得到新聞的標題、連結。而其實還有一個方法可以找到我們想要的新聞簡述,就是有關RSS的套件『FeedParser』。
RSS?
RSS(全稱:RDF Site Summary;Really Simple Syndication[2]),中文譯作簡易資訊聚合[3],也稱聚合內容[4],是一種訊息來源格式規範,用以聚合經常發布更新資料的網站,例如部落格文章、新聞、音訊或視訊的網摘。RSS檔案(或稱做摘要、網路摘要、或頻更新,提供到頻道)包含全文或是節錄的文字,再加上發布者所訂閱之網摘資料和授權的元資料。簡單來說 RSS 能夠讓使用者訂閱個人網站個人部落格,當訂閱的網站有新文章是能夠獲得通知。
實作

我們先看看RSS的架構,基本上都是以xml型態來顯示,例如上圖,我先使用google news所提供的Rss架構來看。
首先大家可以去想要獲取新聞的平台查看他有沒有提供RSS服務,點進去連結之後就會如上圖所示,出現整齊的xml排佈。而每則RSS會有一個『channel』並包著許多的『item』,而item中也有幾個重要的tag,例如title、link、guid、pubdate、description、url,以上這些就是我們獲取新聞的重要資料。
而我以google news rss為例,我們可以使用最笨的方法來修改rss 連結,當作搜尋關鍵字,可以看到上圖的網址,有一個『q=tesla』,這邊就是要搜尋新聞的關鍵字,這方法有在DDCar那篇提到,python如何處理過後產出另一個連結字串。接下來我們就來實作一下feedparser要怎樣使用。
Step1:安裝feedparser套件。
!pip install feedparser
Step2:基本的feedparser使用方法,可以看到下面程式碼,最重要就是要import該套件,再來feedparser最重要的函式就是『parser()』,而參數就是把rss的連結放在這裡面。
import feedparser
def rss(newsurl):
file = feedparser.parse(newsurl)
print(file)
rss('https://news.google.com/rss/search?q=tesla&hl=zh-TW&gl=TW&ceid=TW:zh-Hant')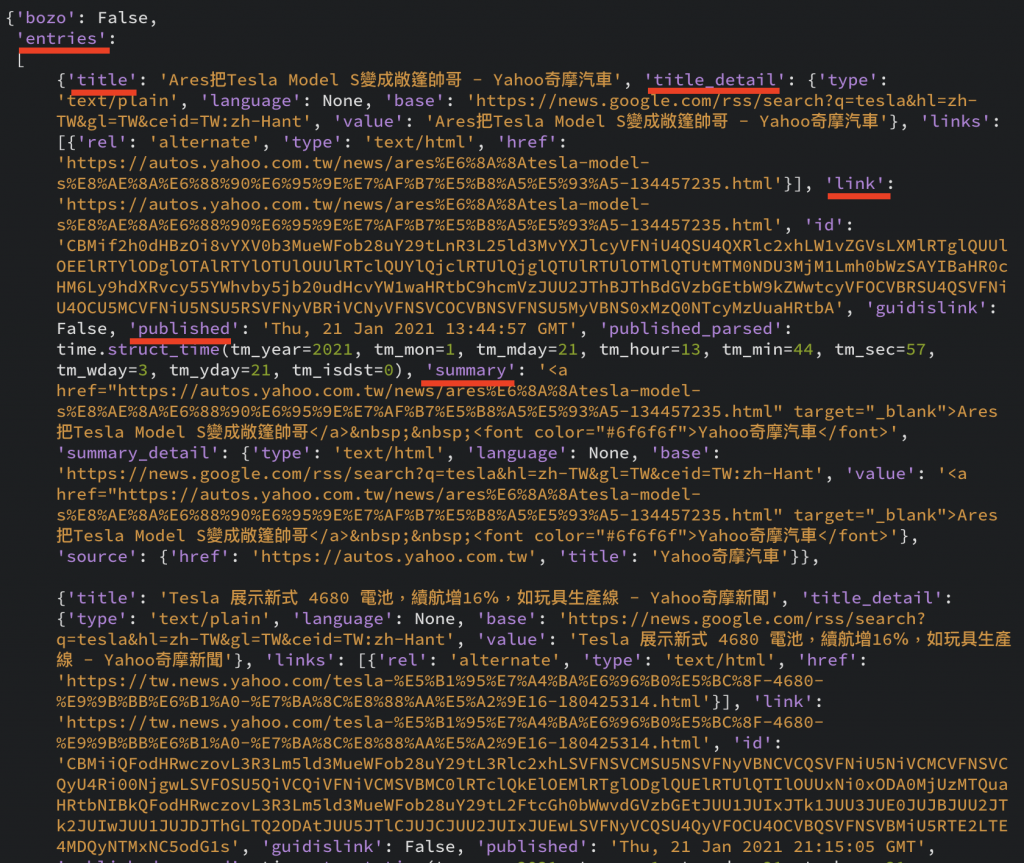
印出來的結果如上圖,看起來很多資料,但主要就看我畫紅線的地方,我們要進去『entries』來抓取其他畫紅線的資料。
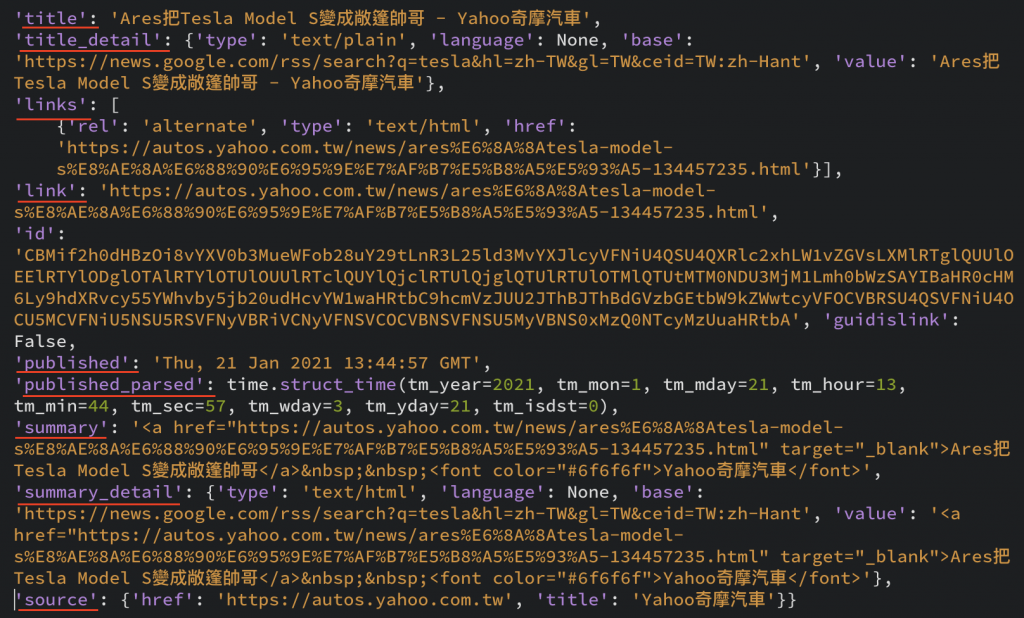
import feedparser
def rss(newsurl):
file = feedparser.parse(newsurl)
for i in file.entries:
print(i.title)#<============i的後面就可以輸入上圖畫線的名稱
rss('https://news.google.com/rss/search?q=tesla&hl=zh-TW&gl=TW&ceid=TW:zh-Hant')在整理清楚一點如上圖二。搭配上方程式碼可以拿到我們想要的資料,例如i.title、i.published等,即可拿到我們想要的資料了。
小結

這次介紹事feedparser最簡單的使用方法,當然爬取內文,就要使用bs4來使用feedparser過濾到的url丟進去,就可以抓取內文了,當然feedparser還有其他進階的用法,之後有使用完後在整理一篇分享。