
簡介
在我們使用爬蟲爬取文章時,當然有非常多的套件可以將原文、標題、圖片等元素個別抓下來,但百密總有一疏,假如是一個內文中含有超連結的內容,就有可能抓不下來,也有可能在後續排列圖文順序時會發生比對不到的情況。

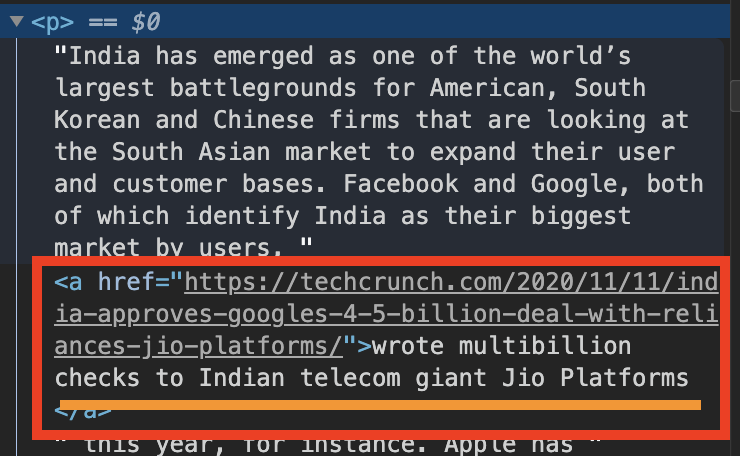
舉個例子,向上圖中的<p>段落中,有時候常常有包含文字的超連結,這時候一般爬曲方式,是抓不到超連結內的文字,而且會導致整段文字都抓不到。而這篇我們想要解決這類的問題,目前解決方法就是使用『Html Parser』,並組合成完整的文字內容,以下就介紹幾種Parser的方式。
Regex方法
Regex
正規表示式(英語:Regular Expression,常簡寫為regex、regexp或RE),又稱正規表達式、正規表示法、規則運算式、常規表示法,是電腦科學的一個概念。正規表示式使用單個字串來描述、符合一系列符合某個句法規則的字串。在很多文字編輯器裡,正則表達式通常被用來檢索、替換那些符合某個模式的文字。
我們可以透過『正規表示式-Regex』將html tag的符號過濾掉,我們看看下方程式碼:
import re
def cleanhtml(raw_html):
cleanr = re.compile('<.*?>')
#cleanr = re.compile('<.*?>|&([a-z0-9]+|#[0-9]{1,6}|#x[0-9a-f]{1,6});')
cleantext = re.sub(cleanr, '', raw_html)
return cleantext以上的程式碼是需要用到python的內建套件『re』,而透過『re.compile(Regex符號)』就可以將html的tag移除。
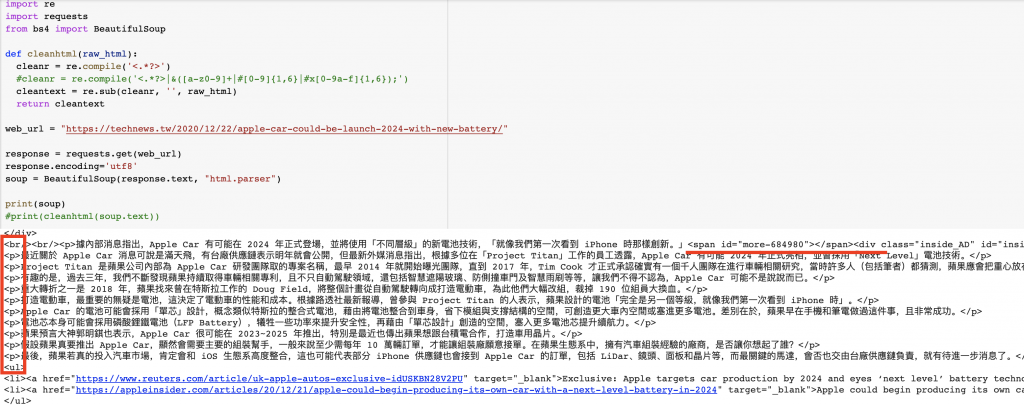
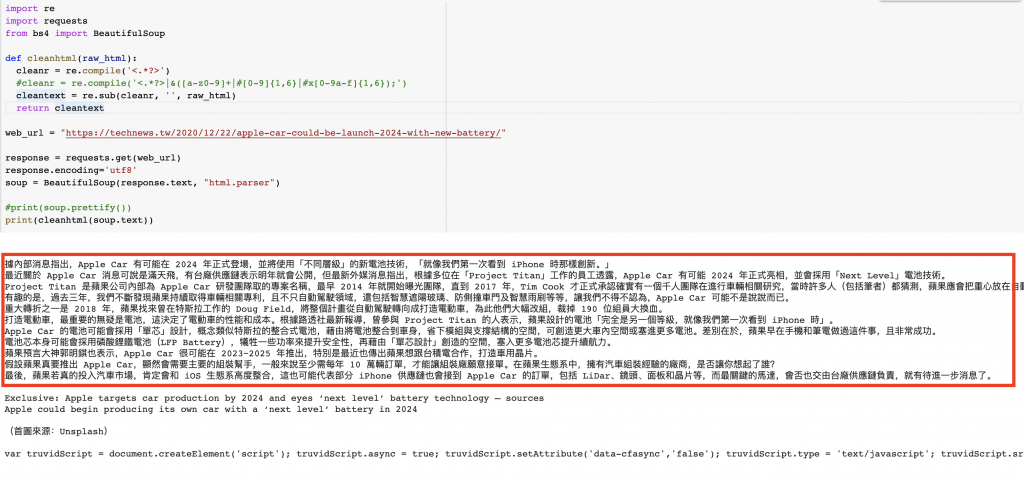
可以看到上圖一,我們直接使用bs4+request套件抓取html原始程式,印出來時可以發現,每段文字前面都含html tag,文字之中有些也還有一些額外的tag,最常出現例如『a 、 span 等等』。而看到使用Regex方法後,如上圖二,將所有的html tag都消掉了,所以我們的抓取內文順序可以先透過bs4鎖定內文區後,再使用該方法處理一次即可。
Beautiful Soup Parser
而我們之前常提到的bs4也是有提供這方法,但真的很不起眼,我們平常只知道要怎樣找尋指定的tag,例如find、find_all、select等等,但其實只要再找到的資料中尾巴加上『.text』就可以過濾出來了。
import requests
from bs4 import BeautifulSoup
web_url = "https://technews.tw/2020/12/22/apple-car-could-be-launch-2024-with-new-battery/"
response = requests.get(web_url)
response.encoding='utf8'
soup = BeautifulSoup(response.text, "html.parser")
for word in soup.find_all('p'):
print(word.text)
如上述程式碼,我們想要找所有的<p>tag,可以看到第一段落,有些p裡面還有一些額外的tag,這些我們都先不管,我們先把所有的p都找到,並透過for-loop將他一筆一筆印出,而在印出的容器尾巴加上『text』,一切就完成了。
re.sub用法
在剛剛的regex方法有使用到re套件,而且是使用re套件中的compile(),其實re套件中還有一個方法也可以將html tag移除。
import re
v = """<p id=1>Sometimes, <b>simpler</b> is better, but <i>not</i> always.</p>"""
result = re.sub("<.*?>", "", v)
print(result)
我們可以來比較一下這兩個方法有什麼不同,下圖一是compile()的方法說明,compile可以把它想成是一個範例,想要用的人就直接將此範例拿來使用,不用輸入regex其他的參數。而sub()除了要放上範例之外,還要將原始文字放在引數中,而且還要放入要repl(replace)的字串,大家可以自行選用哪種方法最適合你的程式碼。


小結
以上提到的2.5種方法供大家參考,這是我在實作其中所遇到的問題,雖然還有非常的多問題,那我們就把它全部解決掉,並且分享給大家,順便記錄一想,之後要用到就可以馬上查,這次介紹的也算一個常用的小技巧。繼續闖關。