
簡介
我們在學了一陣子python之後,當然要拿幾個實際案例來練習驗收一下我們嘗試過的工具,網頁爬蟲假如不使用人家做好的工具包的話,最常使用的就是「requests + beautifualsoup」,並且在實際撰寫程式時也是需要使用到python的基本觀念,這樣才可以想爬什麼就爬什麼。
而這一篇我們就以抓取有關車子的網頁平台「DDcars」來做實驗,這邊我想爬取該平台所有最新消息的文章,而抓取前可以規劃一下爬取步驟與流程,本篇分享爬取第一步,抓標題、文章連結與文章分類標籤。
先了解網頁架構
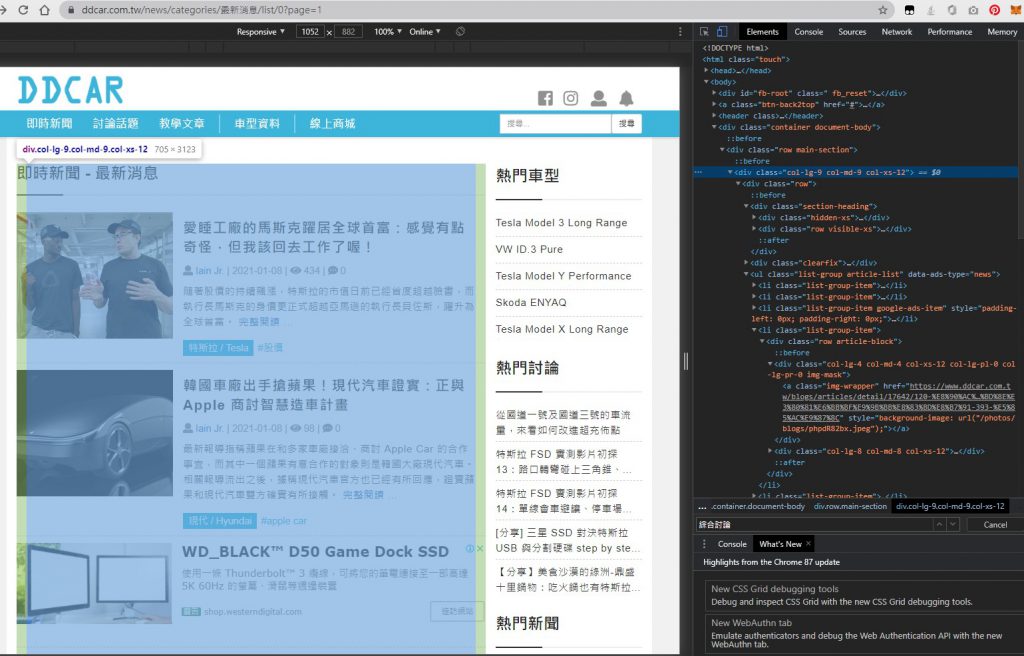
我透過「requests + bs4」來爬文章,由於該套件是解析網址→解析html format,所以我們要去網頁中了解他的網址、與要抓的內容html格式。
解析一-網址:


首先我們可以換頁看看他網址的變化,可以看到切換頁面時,會改變的就是「page = 頁數」,這樣看來只需要做一些網址的加工並丟給request套件來抓html format就可以。
解析二-文章標題與聯結:
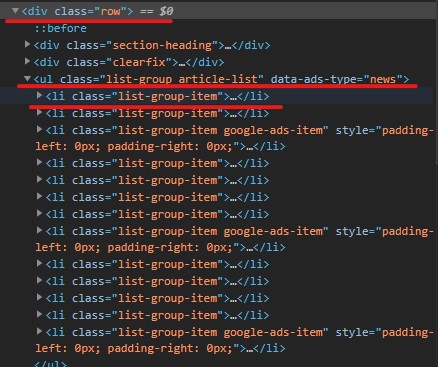
要抓文章的標題與聯結也是要看html格式,可以看到上圖,她文章的篇數是包在一個「div」中,再去看看每一頁是否都是這樣排佈。並且每一則文章是包在「li」下面,所以bs4要找尋的主要就是這兩個tag並搭配css class的名稱來精準結取。
解析三-換頁抓取:
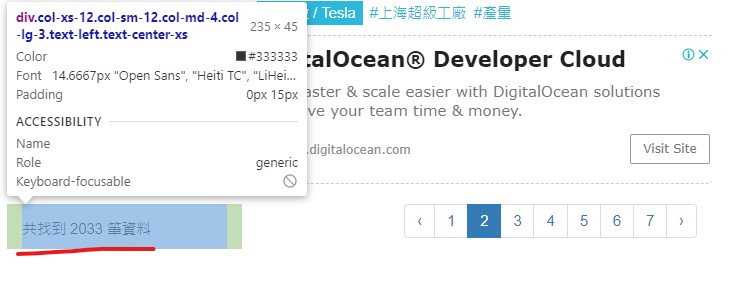
要把本平台的最新新聞都抓下來的話,就要知道她總共有幾篇,或是找一下有什麼方法可以切換頁面,如上圖,該平台有列出目前文章總數,如此一來就可以透過數學算式來進行換頁,且我們知道他的規則就是一個頁面有10篇但是每頁都會穿插廣告,所以要濾掉。
在切換頁面的技術,看到上圖他有一個頁數的區域按鈕,所以也是可以透過Selenium來做瀏覽器的操作。
解析四-抓取文章類別:
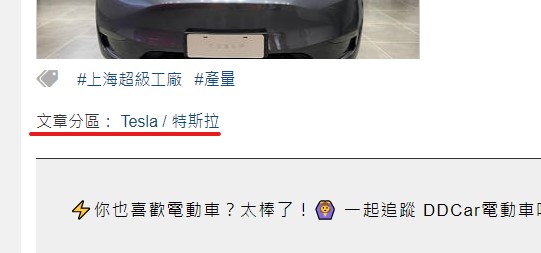
這塊其實可以移到下一篇在講,因為該平台每一則新聞點進去時可以看到下方都會有文章區分的區塊,可以到抓文章內文時在抓,如上圖一所示。
但是能先做的我們可以先做,而且先分類可以在最一開始去辨別分類去抓取該分類文章,如上圖,在文章頁面最上層會呈現這樣,在每個子欄位也會有列出分類標 籤,應用方法有很多,看客倌怎樣應用。
實際操作
由於是我自己把一些輪子做拼裝,所以程式碼的寫法與效能可能不是到最好,但是可以拿到我們想要的資料,而我就依上方解析條列來介紹。
解析1+3實操-網址+換頁:
import requests
from bs4 import BeautifulSoup
import math
import time總之我們先把可能會用到的套件包都先匯入,request+bs4是最主要的工具,math數學運算是要切換頁面要用的,time就是為了不讓整個程式一直跑會出錯,偶而要讓她休息一下。
#文章標題網址陣列
content_list = []
#文章類別陣列
tag_list = []
#參數區
pagenum = 1
page_sd_count = 10
all_article_count = 0
all_pagecount = 0先把要用到的容器命名一下。
def single_page_crawler(page):
web_url = "https://www.ddcar.com.tw/news/categories/%E6%9C%80%E6%96%B0%E6%B6%88%E6%81%AF/list/0?page="
all_url = web_url + str(page)為了讓程式更簡短,我會用def來讓程式要重複執行的動作包在裡面,而該函示要輸入的就是「頁數」,並透過資料型態的切換整合後,會產出完整的頁面網址。
#main
web_url = "https://www.ddcar.com.tw/news/categories/%E6%9C%80%E6%96%B0%E6%B6%88%E6%81%AF/list/0?page=1"
all_url = web_url + str(pagenum)
response = requests.get(all_url)
response.encoding='utf8'
soup = BeautifulSoup(response.text, "html.parser")
article_count = soup.find("p",class_='total-records')
#提取字串中的數字
num = ''.join([x for x in str(article_count) if x.isdigit()])
#計算有幾頁
all_pagecount = math.ceil(int(num)/10)
print(all_pagecount)
for i in range(1,all_pagecount):
single_page_crawler(pagenum)
pagenum += 1
time.sleep(10)
而我們要抓取該平台所有文章的筆數,就要先把某一頁的網址先丟到bs4來取頁數的「數字」。這邊bs4的用法我就省略,之前有分享過文章一、文章二。
article_count = soup.find("p",class_='total-records')
#提取字串中的數字
num = ''.join([x for x in str(article_count) if x.isdigit()])
#計算有幾頁
all_pagecount = math.ceil(int(num)/10)上面就是專門在算頁數的程式碼,其實很簡單,就是我們透過bs4抓到總筆數,把他轉換成「int」,那要怎樣轉呢,可以用到「isdigit()」來抓取字串中的數字,找到之後並轉換成數字資料型態,最後把它做數學運算,總筆數/每頁會顯示則數在無條件進位,就會得出所有的頁數。
解析2實操-文章標題與聯結:
#文章標題與網址
for x in soup.find_all("ul",class_="list-group article-list",limit=1):
for y in x.find_all("h4"):
content_list.append(y)這段程式碼就要放在剛剛的「def」函式中,因為這個部分是要透過頁數切換都要抓取的內容。這邊我們因為要找的東西被html格式包在比較內層,就要使用雙層for-loop,先找到並撥開包裝10則文章的「ul」,在撥開每一個「li」中的「h4」,如此就可以得到文章的標題與聯結,最後我們把每一則存到「content_list」陣列中。
解析4實操-文章類別:
#文章tag
for x in soup.find_all("ul",class_="list-group article-list",limit=1):
for y in x.find_all("div",class_="related-tags-list"):
if y.find("a").text != "綜合討論":
print(y.find("a").text)這端程式碼一樣要包在「def」中,跟實操2一樣,解析的方法也是一樣的,只是html tag名稱與css-class名稱不同而已,但要過濾掉每一頁都會出現的「綜合討論tag」,所以就多加了一個判斷式。
程式碼整合
import requests
from bs4 import BeautifulSoup
import math
import time
#文章標題網址陣列
content_list = []
#文章類別陣列
tag_list = []
#參數區
pagenum = 1
page_sd_count = 10
all_article_count = 0
all_pagecount = 0
def single_page_crawler(page):
web_url = "https://www.ddcar.com.tw/news/categories/%E6%9C%80%E6%96%B0%E6%B6%88%E6%81%AF/list/0?page="
all_url = web_url + str(page)
response = requests.get(all_url)
response.encoding='utf8'
soup = BeautifulSoup(response.text, "html.parser")
#文章標題與網址
for x in soup.find_all("ul",class_="list-group article-list",limit=1):
for y in x.find_all("h4"):
content_list.append(y)
#print(content_list)
#print(len(content_list))
#文章tag
for x in soup.find_all("ul",class_="list-group article-list",limit=1):
for y in x.find_all("div",class_="related-tags-list"):
if y.find("a").text != "綜合討論":
#print(y.find("a").text)
#main
web_url = "https://www.ddcar.com.tw/news/categories/%E6%9C%80%E6%96%B0%E6%B6%88%E6%81%AF/list/0?page=1"
all_url = web_url + str(pagenum)
response = requests.get(all_url)
response.encoding='utf8'
soup = BeautifulSoup(response.text, "html.parser")
article_count = soup.find("p",class_='total-records')
#提取字串中的數字
num = ''.join([x for x in str(article_count) if x.isdigit()])
#計算有幾頁
all_pagecount = math.ceil(int(num)/10)
#print(all_pagecount)
for i in range(1,all_pagecount):
single_page_crawler(pagenum)
pagenum += 1
time.sleep(10)小結&結果
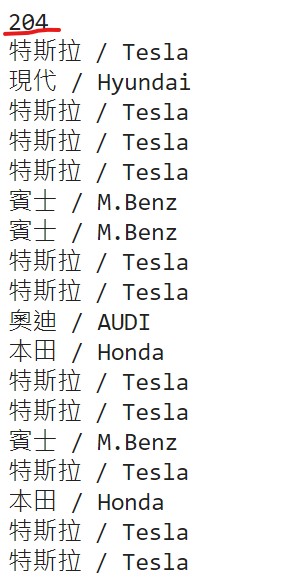

本篇所介紹的程式設計(拼裝)第一階段算是完成了,可以看到我們的成果如上圖所示,圖一顯示我們可以在陣列中依序印出每一篇的類別,並看到上圖二,也可以抓取到每一則的標題與網址,透過兩個list就可以對應標題+網址的索引對應到每一篇的類別了。在下個階段我們將進行從抓取下來的每篇網址繼續抓取文章內文、圖片、日期等資料。