
簡介
在接觸AI的自然語言(NLP-Natural Language Processing)時,有很多的套件都有關於自然語言的訓練與使用,自然語言對大家可能有點陌生,我們日常生活中最常接觸的應用有Chatbot、 Alexa、Siri 等語音助理背後的關鍵技術都是使用該自然語言技術。
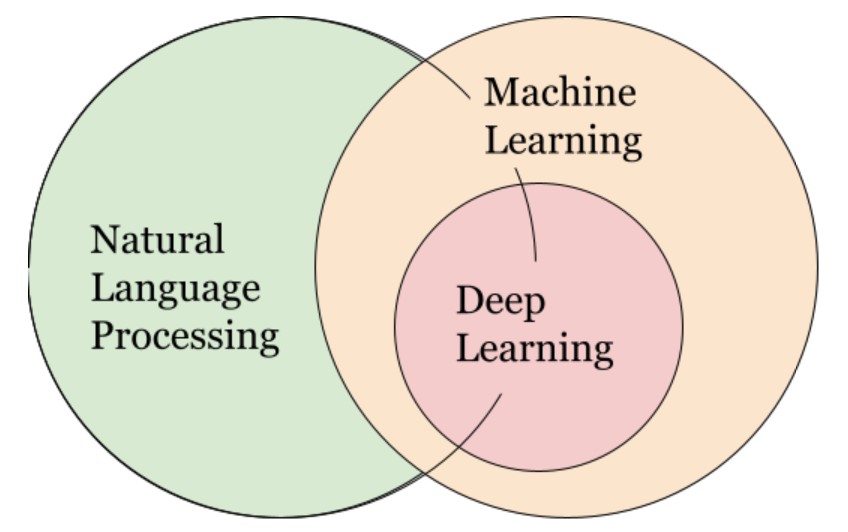
上圖是自然語言與機器、深度學習的關係;自然語言處理是語言學、電腦科學和人工智慧的一個分支領域,允許通過軟體自動處理文字。NLP使機器能夠閱讀、理解和響應雜亂無章的非結構化文字。 在我們之前介紹過的一些套件通常都不外乎離不開文字、句子的預處理。
預處理項目
分段:給定一長串字元,我們可以用空格分隔檔案,按句點分隔句子,按空格分隔單詞。實現細節將因資料集而異。
使用小寫:大寫通常不會增加效能,並且會使字串比較更加困難。所以把所有的東西都改成小寫。
刪除標點:我們可能需要刪除逗號、引號和其他不增加意義的標點。
刪除停用詞:停用詞是像「she」、「the」和「of」這樣的詞,它們不會增加文字的含義,並且分散對關鍵字的注意力。
刪除其他不相關單詞:根據你的應用程式,你可能希望刪除某些不相關的單詞。例如,如果評估課程回顧,像「教授」和「課程」這樣的詞可能沒有用。
詞幹/詞根化:詞幹分析和詞根化都會生成詞形變化單詞的詞根形式(例如:「running」到「run」)。詞幹提取速度更快,但不能保證詞根是英語單詞。詞根化使用語料庫來確保詞根是一個單詞,但代價是速度。
詞性標註:詞性標註以詞性(名詞、動詞、介詞)為依據,根據詞義和語境來標記單詞。例如,我們可以專注於名詞進行關鍵字提取。

簡單來說,NLP就是將你的文字、句子做上圖的判斷,從各個單字、個個單詞、大到一整句話來作處理,而本篇會介紹Python提供的套件庫中的「NLTK」來實際應用,但不包含AI訓練。
實操
Step1:這邊我透過jupyter notebook來操作,首先請安裝nltk套件,如下程式碼。
!pip install nltkStep2:匯入套件,並下載其他巨人已經包裝好的分辨字、詞、句包。
import nltk
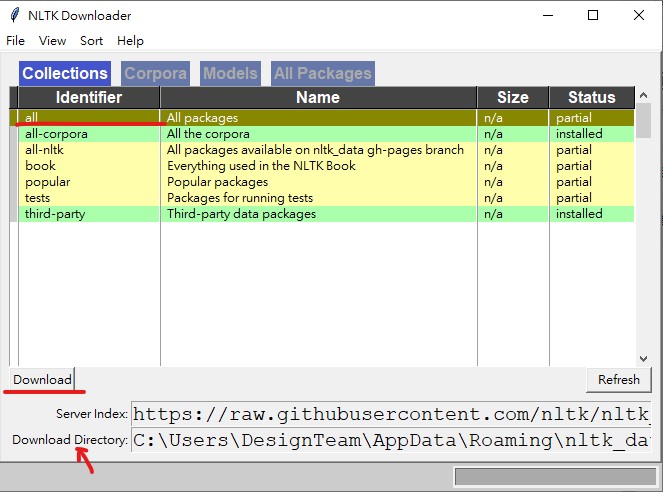
nltk.download()Step3:執行完上一段程式碼後會跳出一個下載視窗,如下圖,可以點選「all」並按下「Download」,而下載下來的檔案會放在隱藏資料夾中,你也可以更改他的路徑。假如都下載好的話,每個項目都會變成綠底標示。你也可以切換到不同類別檢查一下是否有下載好。

Step4:先使匯入最基本的兩個功能,分別是斷詞與斷句。下面就直接以程式碼顯示。
#斷句
from nltk.tokenize import sent_tokenize
#斷詞
from nltk.tokenize import word_tokenize
#範例文章
mytext = """
Apple has gifted the world with a library of devices that have since become household names, many of which we use daily. There’s the iPhone, iPad, MacBook Pro, and AirPods; but when you think Apple, Car is not the first word to come to mind. That might soon change as recent news has breathed new life into over ten years of rumors surrounding Apple’s attempt at an electric car. Here’s everything we know so far, along with the winding road of a backstory that brought us to this point.
"""
#斷句實際使用
sent_tokenize(mytext)
#斷詞實際使用
word_tokenize(mytext)
可以看到上圖,就可以正常的將文章分化成你想要的解析模式。
Step5:接著你假如要再進一步使用nltk的其他功能的話,還可以使用詞性的分析,如下程式碼。要使用「pos_tag()」。
text = word_tokenize(mytext)
nltk.pos_tag(text)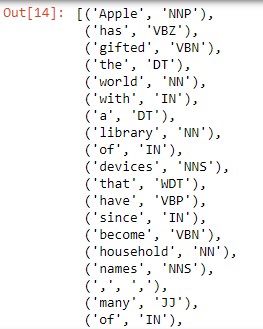
可以看到印出來的詞性,我們似乎非常難理解,而下面整理了所有詞性的「意思」。
CC coordinatingconjunction 並列連詞
CD cardinaldigit 純數基數
DT determiner 限定詞(置於名詞前起限定作用,如 the、some、my 等)
EX existentialthere (like:"there is"... think of it like "thereexists") 存在句;存現句
FW foreignword 外來語;外來詞;外文原詞
IN preposition/subordinating conjunction介詞/從屬連詞;主從連詞;從屬連線詞
JJ adjective 'big' 形容詞
JJR adjective, comparative 'bigger' (形容詞或副詞的)比較級形式
JJS adjective, superlative 'biggest' (形容詞或副詞的)最高階
LS listmarker 1)
MD modal (could, will) 形態的,形式的 , 語氣的;情態的
NN noun, singular 'desk' 名詞單數形式
NNS nounplural 'desks' 名詞複數形式
NNP propernoun, singular 'Harrison' 專有名詞
NNPS proper noun, plural 'Americans' 專有名詞複數形式
PDT predeterminer 'all the kids' 前位限定詞
POS possessiveending parent's 屬有詞結束語
PRP personalpronoun I, he, she 人稱代詞
PRP$ possessive pronoun my, his, hers 物主代詞
RB adverb very, silently, 副詞非常靜靜地
RBR adverb,comparative better (形容詞或副詞的)比較級形式
RBS adverb,superlative best (形容詞或副詞的)最高階
RP particle give up 小品詞(與動詞構成短語動詞的副詞或介詞)
TO to go 'to' the store.
UH interjection errrrrrrrm 感嘆詞;感嘆語
VB verb, baseform take 動詞
VBD verb, pasttense took 動詞過去時;過去式
VBG verb,gerund/present participle taking 動詞動名詞/現在分詞
VBN verb, pastparticiple taken 動詞過去分詞
VBP verb,sing. present, non-3d take 動詞現在
VBZ verb, 3rdperson sing. present takes 動詞第三人稱
WDT wh-determiner which 限定詞(置於名詞前起限定作用,如 the、some、my 等)
WP wh-pronoun who, what 代詞(代替名詞或名詞片語的單詞)
WP$ possessivewh-pronoun whose 所有格;屬有詞
WRB wh-abverb where, when 副詞Step6:NLTK也提供了「視覺化的字詞語意分析樹」,用法如下:
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[1]
t.draw()
小結
| 語言處理任務 | nltk模組 | 功能描述 |
| 獲取和處理語料庫 | nltk.corpus | 語料庫和詞典的標準化介面 |
| 字串處理 | nltk.tokenize,nltk.stem | 分詞,句子分解提取主幹 |
| 搭配發現 | nltk.collocations | 用於識別搭配工具,查找單詞之間的關聯關係 |
| 詞性識別字 | nltk.tag | 包含用於詞性標注的類和介面 |
| 分類 | nltk.classify,nltk.cluster nltk.classify | 用類別標籤標記的介面;nltk.cluster包含了許多聚類演算法如貝葉斯、EM、k-means |
| 分塊 | nltk.chunk | 在不受限制的文本識別非重疊語言組的類和介面 |
| 解析 | nltk.parse | 對圖表、概率等解析的介面 |
| 語義解釋 | nltk.sem,nltk.inference | 一階邏輯,模型檢驗 |
| 指標評測 | nltk.metrics | 精度,召回率,協議係數 |
| 概率與估計 | nltk.probability | 計算頻率分佈、平滑概率分佈的介面 |
| 應用 | nltk.app,nltk.chat | 圖形化的關鍵字排序,分析器,WordNet檢視器,聊天機器人 |
| 語言學領域的工作 | nltk.toolbox | 處理SIL工具箱格式的資料 |
這篇先分享較為出淺的入門函式,上表示NLTK較為完整的函式,其實這個套件有點像Jeiba,但比Jeiba可以做的事還要更多,但有難透過一篇把全部講完。而這個套件其實也是可以解析中文,但必須結合Jeiba套件運用,在之後有機會可以分享一下。